Conteúdo
- Introdução
- Aprendizado de Máquina Contemporâneo
- Neurônios
- Redes Neurais Artificiais
- Treinamento
- Implementando uma Rede Neural Artificial
- Referências
Introdução
Antes de começarmos, é necessário ter uniformidade em nossa liguagem. Por isso, peço que leia a introdução ao aprendizado de máquina que fiz especialmente para quem quer iniciar o entendimento sobre o assunto. Lá, falo sobre o que é e para que serve aprendizado de máquina e apresento alguns do principais conceitos dessa ciência, como os três tipos de aprendizado, o dilema de viés e variância, treinamento, avaliação e validação cruzada. Reconheço que é um post um pouco longo, mas, por favor, invista um pouco do seu tempo nele e entenda bem os conceitos lá apresentados.
Bom, espero que você tenha lido o que recomendei. A partir desse ponto, utilizarei alguns dos termos apresentados (e que, talvez, você tenha acabado de aprender). Isso me permitirá tornar este post mais curto, já que não precisarei explicar todos os conceitos de aprendizado de máquina do zero.
Aviso: Ao final deste post, você entenderá intuitivamente o que é uma rede neural e será capaz de treinar uma para reconhecimento de imagem. Mesmo assim, esse post é apenas uma breve introdução ao aprendizado de máquina contemporâneo. Pensei nele como uma forma de instigar a sua curiosidade e lhe convencer de que aprendizado de máquina é um assunto no qual vale a pena se aprofundar. Assim, do fundo do meu coração, não terminem essa leitura achando que já sabem o suficiente e, por favor, continuem aprendendo mais, bem mais, do que o conteúdo apresentado aqui.
Aprendizado de Máquina Contemporâneo
A maioria dos algoritmos de aprendizado de máquina são do século passado. Alguns, como redes neurais, são especialmente velhos, tendo sido inventados na década de 50. Por que, então, só agora observamos aprendizado de máquina em todos os cantos e seu anúncio em revistas e jornais aos quatro ventos? Podemos argumentar que, embora os algoritmos em si sejam velhos, algumas pequenas melhorias mais recentes os tornaram, finalmente, extremamente úteis. Isso é parcialmente verdade, mas foram outros dois fatores que mais contribuíram para o atual renascimento da inteligência artificial:
- Aumento do poder computacional (leia-se GPUs enormes)
- Aumento da disponibilidade de dados (leia-se Big Data ou simplesmente bases de dados maiores)
Infelizmente, ainda hoje, para que um modelo de aprendizado de máquina consiga extrapolar um padrão aprendido, ele precisa de uma abundância de exemplos desses padrões. Por exemplo, para que um sistema inteligente consiga interpretar uma palavra, ele necessita antes visualizar milhões de frases para entender como as plavras se relacionam. Isso só foi possível recentemente, com a expansão da quantidade de dados e da capacidade computacional para processá-los.
Devemos ter em mente que os sistemas de inteligência artificias contemporâneos não são nada mais do que modelos matemáticos complexos que conseguem aprender uma representação simplificada da realidade, a partir da extração de padrões estatísticos presentes nos dados, que são, por sua vez, extraídos dessa mesma realidade que motiva o aprendizado. E, por enquanto, um ponto fraco desses sistemas ou modelos estatísticos é que eles precisam de muitos dados para conseguir entender os padrões que se apresentam na nossa complexa realidade.
Mas como exatamente esses sistemas conseguem entender a nossa realidade? Infelizmente, ainda não podemos dizer com certeza como isso é feito. Agora explicarei da forma mais aceita e cujas evidenciais são mais fortes. Em poucas palavras, os sistemas de inteligência artificial modernos primeiro aprendem uma representação interna abstrata dos dados brutos e, a partir dessa representação abstrata, realizam alguma tarefa, geralmente uma previsão. Por exemplo, considere a tarefa de prever que objeto está em uma imagem. Nesse caso, os dados são simples pixeis com quantidades de vermelho, verde e azul (se a imagem for preta e branca, os pixeis são ainda mais simples, indicando apenas a quantidade de preto). Como é muito difícil sair desses dados brutos para conceitos abstratos - como a transparência de uma garrafa pet, um olho em uma face, o telhado de uma casa -, o sistema antes converte os pixeis de uma imagem em algo mais abstrato, como o conceito visual de um olho.
Isso é provavelmente o que eu e você fazemos quando enxergamos. O nosso corpo percebe raios multicoloridos refletidos nos objetos, mas o que vemos são conceitos com uma carga semântica muito maior, tais como a textura da madeira em uma cadeira ou a silhueta opaca de um gato branco passeando sob a meia luz. Para representar esse nível de abstração, os sistemas contemporâneos de IA são geralmente construídos em camadas. Podemos pensar nelas como níveis hierárquicos de abstração que serão aprendidos por um modelo estatístico. Por exemplo, a primeira camada de um sistema pode aprender a abstrair pixeis em cantos e quinas de objetos ou diferenças de contraste e luminosidade; a segunda camada, partido das abstrações da primeira, converte os cantos e quinas em formas mais elaboradas, como círculos, triângulos e quadrados; a terceira camada então pode partir dessas formas para criar abstrações sobre parte de objetos, como a roda de um carro ou o bico de um papagaio; por fim, o sistema usa essas abstrações finais para identificar o que está em uma foto colorida. (Isso é mais do que um mero exemplo. Na verdade, existem formas um tanto divertidas de ver as abstrações aprendidas por IAs).
Esse modo de estruturar os sistemas de IA é o que leva o nome de Deep Learning (aprendizado profundo) ou aprendizado de representações. A palavra “profundo” vem do simples fato de construímos nossos sistemas empilhando camadas.
Neurônios
Nesta introdução, para exemplificar a construção e o treinamento de um sistema moderno de IA, realizaremos uma simples tarefa de visão computacional, na qual usaremos uma rede neural bem simples para reconhecer dígitos escritos. Em termos técnicos, será uma tarefa de OCR (Optical Character Recognition). Mas, antes de entendermos o que são e como treinar redes neurais, precisamos falar sobre seu componente mais básico: os neurônios.
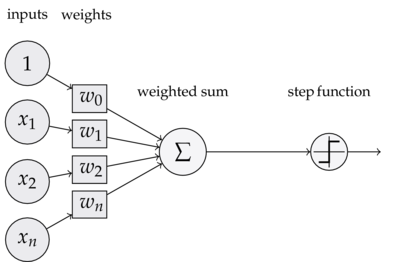
Como grande parte dos algoritmos de aprendizado de máquina, os neurônios são modelos matemáticos (ou funções) que representam a realidade de forma simplificada. Eles são compostos por uma soma ponderada, seguida ou não de uma função ativação. Por exemplo, considere a tarefa de prever se o preço de uma casa será maior ou menor do que a média, dadas as variáveis \(x_1\), o tamanho da casa em metros quadrados, \(x_2\), o índice de pobreza da vizinhança e \(x_3\) o tamanho do meu cabelo. Podemos facilmente utilizar um neurônio para resolver essa tarefa. Note que, provavelmente, quanto maior \(x_1\), maior a probabilidade da casa ter um preço acima da média (e vice versa). Assim, devemos esperar que o peso de \(x_1\), \(w_1\), na soma ponderada do nosso neurônio seja positivo, indicando que essa variável tem um impacto igualmente positivo na probabilidade do preço da casa ser acima da média. Com o mesmo raciocínio, podemos argumentar que \(w_2\) será negativo. Note que esses dois pesos não precisam ter a mesma intensidade. Pode ser que o impacto positivo de \(x_1\) seja muito maior que o impacto negativo de \(x_2\), de forma que \(w_1\) seja maior que \(w_2\). Em outras palavras, pode ser que o tamanho da casa seja um determinante mais importante do preço do que o índice de pobreza da vizinhança. Por fim, é provável que o tamanho do meu cabelo, \(x_3\), não tenha muito impacto no preço de uma casa. Por isso, esperamos que \(w_3\) seja muito próximo de zero na soma ponderada do nosso neurônio. Isso indica que essa variável influencia pouco o preço da casa. Repare também que temos uma variável que é sempre \(1\). A ponderação desse \(1\) com o \(w_0\) é o que chamamos de viés. Esse viés captura a tendência da casa ter valor alto, uma vez que já consideramos as outras variáveis. Por fim, é importante ressaltar que os \(w\)s são o que chamamos de parâmetros do modelo. Eles são variáveis que o neurônio (e, mais para frente, a rede neural) vai aprender (ou estimar) durante o treinamento.
Além da soma ponderada, nosso neurônio precisa de uma função de ativação. Isso porque a soma ponderada pode nos dar um resultado qualquer, mas, como nossa previsão é uma probabilidade, precisamos de uma função ativação que converta um número qualquer, positivo ou negativo, em um valor entre 0 e 1. Essa função é denominada função softmax, que será utilizada após a soma ponderada do nosso neurônio. Existem várias funções de ativação e, dependendo da tarefa em questão, uma é mais recomendada do que outra. Infelizmente, para falar delas é preciso mais conhecimento matemático. Intuitivamente, quando as mencionamos em redes neurais, imagine a função ativação como algo que dá um comportamento mais complexo aos neurônios. Elas também são fundamentais nas redes neurais, para que essas consigam representar padrões complexos.
Redes Neurais Artificiais
Infelizmente, os neurônios são bastante limitados. Em aprendizado de máquina, queremos que um algoritmo possa aprender qualquer tipo de padrão presente nos dados, mas isso não é possível com um simples neurônio. Por isso, construímos as redes neurais, que são simplesmente vários neurônios conectados. Pense nos neurônios como blocos de Lego e nas redes neurais como estruturas que montamos empilhando esses blocos de Lego. Dependendo da tarefa, uma estrutura pode se mais útil do que outra. No entanto, aqui, vamos considerar apenas a estrutura mais simples e mais comum de rede neural, o modelo de redes neurais feedforward densas.
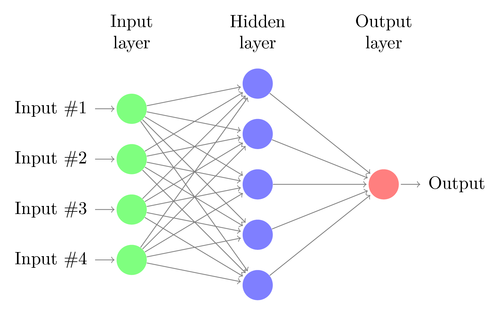
Na rede neural acima, como exemplo, dizemos que ainda lidamos com o problema de prever se o preço de uma casa será acima ou abaixo da média. Na entrada da rede, temos as mesmas 3 variáveis mais o viés, que são representados pelas bolinhas verdes. Isso é o que chamamos de camada de entrada da rede neural. Posteriormente, utilizando 5 neurônios, realizamos 5 somas ponderadas seguidas de uma função de ativação. Essas operações são representadas pelas bolinhas azuis, que recebem o nome de camada oculta da rede neural. Por fim, usamos um único neurônio que realiza uma soma ponderada do resultado dos neurônios anteriores e então converte essa soma ponderada em uma probabilidade com a função softmax. Isso é o que chamamos de camada de saída da rede neural e está representado pela bolinha vermelha.
Ignore a camada de entrada (verde) por um momento. Você notou como a camada de saída mais a camada oculta são exatamente o modelo de neurônio que vimos anteriormente? A camada de saída é simplesmente um modelo de neurônio, que está tratando a camada oculta como se fosse as variáveis independentes que determinam a variável de resposta (no nosso exemplo, a probabilidade do preço da casa ser alto). Assim, podemos observar que a rede neural está aprendendo novas variáveis e usando um modelo de neurônio nessas novas variáveis. Esse é o princípio básico de deep learning: aprender variáveis representativas, geralmente mais abstratas, que auxiliem na tarefa em questão, no caso, uma tarefa de previsão.
Podemos ir um passo além e adicionar uma segunda camada oculta.
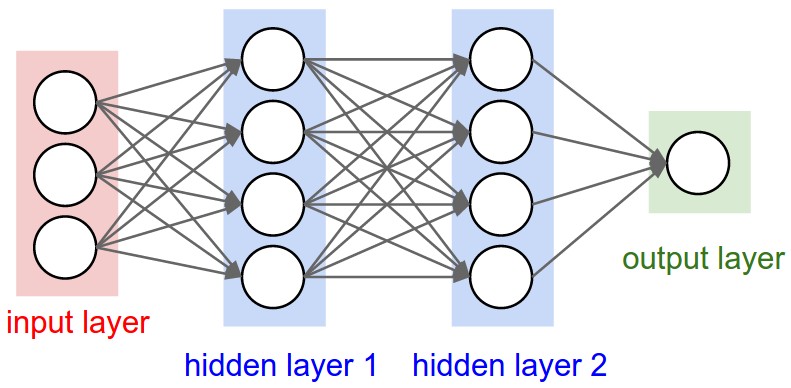
Isso aumenta ainda mais o poder representativo da rede neural. Lembre-se de que podemos pensar nas camadas da rede neural como níveis hierárquicos de abstração.
Treinamento
Agora que entendemos o que são redes neurais em um nível intuitivo, iremos treiná-las. Isso é feito por um processo de otimização no qual minimizamos uma função custo (ou objetivo). Para manter o nível de simplicidade, pense na função custo como algo que mede a diferença entre o que a rede neural prevê e o que de fato foi observado. Por exemplo, se a rede neural prever um valor pequeno para a probabilidade de uma casa ter preço acima da média, mas a casa, na verdade, for bastante cara, então a função custo terá um valor alto.
Para iniciar o treinamento, vamos chutar alguns valores para os \(w\)s de cada neurônio. Em seguida, observaremos a previsão da rede neural em alguns dados, que, muito provavelmente, será péssima. Dessa forma, os \(w\)s iniciais serão associados a um alto custo ou a uma região elevada na superfície de custo. No treinamento então, vamos atualizar os \(w\)s de maneira iterativa, de forma a diminuir o custo. Isso é feito com a técnica de gradiente descendente estocástico, que pode ser entendida como uma descida na superfície de custo de uma tarefa de otimização.
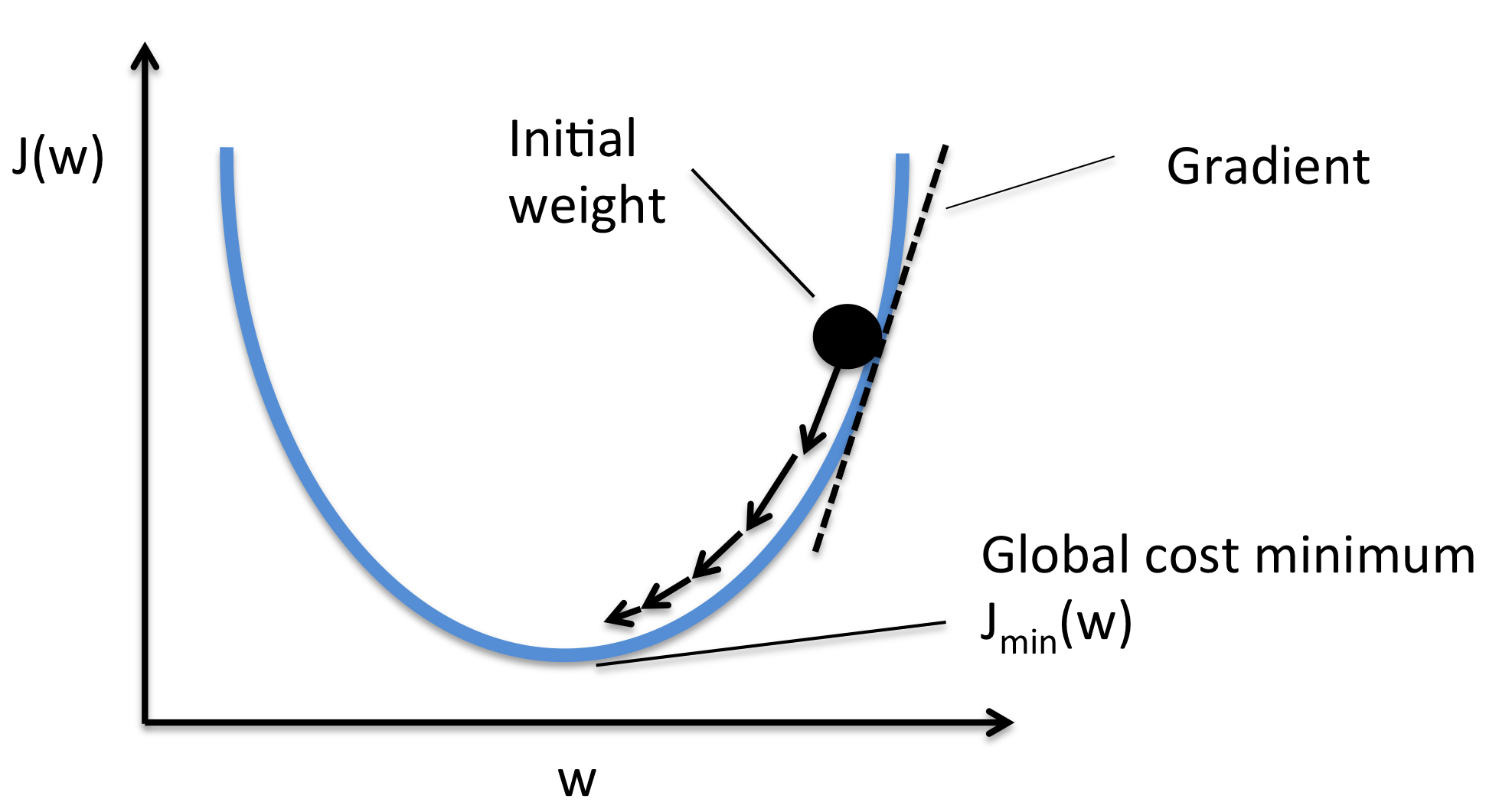
Para entender a fundo essa técnica, é preciso saber cálculo multivariado, mas, intuitivamente, ela é bem simples. Em primeiro lugar, escolhemos aleatoriamente (daí a palavra estocástico) um pequeno punhado de dados para conseguir uma estimativa da nossa posição na superfície de custo. Então, movemos os parâmetros \(w\) na direção oposta da inclinação dessa superfície. Isso é como dar um passo para baixo na superfície de custo. Com passos suficientes, nossa esperança é que os \(w\) nos coloque em uma região de custo (ou erro) baixa o suficiente.
Implementando uma Rede Neural Artificial
Muito bem, tudo isso já parece bastante promissor. Vamos então construir e treinar uma rede neural de duas camadas ocultas para uma tarefa simples de reconhecimento de caracteres em imagens. Para isso, utilizarei a linguagem de programação Python, mas não se preocupe, não será preciso saber programar para entender o que vem a seguir. Na verdade, quase não vou usar programação. Peço então que, por hora, você pense no Python apenas como um programa de computador como outro qualquer. Com ele, podemos digitar uma série de comandos para que o computador os execute. Aqui, vou simplesmente mostrar quais são os comando necessários para construir e treinar uma simples rede neural.
Junto com o Python, utilizarei alguns pacotes para ajudar na construção e treinamento de redes neurais. Você pode pensar nesses pacotes como extensões de um programa de computador. Mais concretamente, pense em um pacote do Python como uma fonte nova que você baixa para seu editor de texto. Particularmente importante será o pacote TensorFlow, que foi desenvolvido pelo Google e feito open source (aberto) em 2015.
Se você ainda não tem esses programas, não se preocupe. Também fiz um tutorial sobre como instalá-los. Sugiro que você instale os programas necessários e acompanhe o tutorial a seguir executando cada passo no seu computador.
Sem mais delongas, no Python, importaremos alguns pacotes:
import tensorflow as tf # importa o TensorFlow
from tensorflow.contrib.learn import DNNClassifier # importa o modelo de rede neural do TensorFlow
# pacotes adicionais
import numpy as np # para computação numérica menos intensiva
import os # para criar pastas
OBS: em uma sequência de comandos (código) de Python, o computador ignora tudo que for escrito após #, por isso, # indica o início de um comentário meu explicando o código.
Os dados
Em primeiro lugar, vamos ver como são nossos dados. Já disse que trabalharemos com OCR. Em particular, utilizamos a base de dados MNIST, que contém 55 mil dados de treino e 10 mil dados de teste. Os dados são imagens de 28x28 pixeis, o que nos dá 784 variáveis para colocar na camada de entrada da nossa rede neural. Mas, antes disso, vamos criar uma nova pasta no nosso computador e baixar esses dados nela.
# criamos uma pasta para colocar os dados
if not os.path.exists('tmp'): # se a pasta não existir
os.makedirs('tmp') # cria a pasta
# baixa os dados na pasta criada
from tensorflow.examples.tutorials.mnist import input_data # baixa os dados
data = input_data.read_data_sets("tmp/", one_hot=False) # baixa e carrega os dados já formatados
Após executar os comandos acima, todos os dados, tanto de treino como de teste, estão armazenados em data. Você pode pensar em data como uma planilha do Excel aberta. As únicas diferenças são que você não pode interagir com a linhas e colunas da planilha clicando com o mouse e que você não pode ver a planilha a todo tempo. No entanto, podemos facilmente ver como são nossos dados usando o comando print() do Python. Para interagir com os dados em data, usamos a notação de ponto .. Por exemplo, data.train.images nos dá acesso aos dados de treino e, a partir daí, às imagens de treino. Podemos ir além e usar data.train.images.shape para ver o atributo de tamanho dos dados de treino.
print(data.train.images.shape) # mostra o formato dos dados de treino
print(data.test.images.shape) # mostra o formato dos dados de teste
print(data.train.images) # mostra algumas linhas e colunas dos dados de treino
(55000, 784)
(10000, 784)
[[ 0. 0. 0. ..., 0. 0. 0.]
[ 0. 0. 0. ..., 0. 0. 0.]
[ 0. 0. 0. ..., 0. 0. 0.]
...,
[ 0. 0. 0. ..., 0. 0. 0.]
[ 0. 0. 0. ..., 0. 0. 0.]
[ 0. 0. 0. ..., 0. 0. 0.]]
Acima, observamos que os dados de treino são uma tabela com 55 mil linhas, cada uma com uma observação de 784 colunas, (que representam os pixeis de uma imagem). Como nossa tarefa se encaixa no regime de aprendizado supervisionado, cada imagem vem anotada com um alvo, o dígito que está nela (e que queremos prever). Podemos acessar os alvos de treino com o comando print() mais data.train.labels.
print(data.train.labels.shape) # mostra o formato dos alvos de treino
print(data.train.labels) # mostra os alvos de treino
(55000,)
[7 3 4 ..., 5 6 8]
As anotações da base de treino podem ser entendidas como uma tabela de 55 mil linhas e com uma única coluna. Pelo que vemos acima, nossa primeira imagem é um 7, nossa segunda imagem é um 3 e assim por diante. Com o intuito de minimizar o nível de abstração, analisaremos como são essas imagens. Para tanto, necessitamos de um pacote do Python para visualizar as imagens. Abaixo, importamos esse pacote, desenhamos a segunda imagem de treino com o comando plt.imshow(...) (usamos índice 1 para selecionar a segunda imagem, pois em ciência da computação a contagem é iniciada a partir do zero), usamos o alvo correspondente como título da imagem com plt.title(...) e, por fim, usamos plt.show() para mostrar a imagem. Além disso, na imagem, usamos .reshape(28,28) para reformatá-la de uma linha com 784 pixeis para uma grade com 28px de altura e largura.
from matplotlib import pyplot as plt # importa pacote para mostrar imagens
# mostra a primeira imagem no set de treino
plt.imshow(data.train.images[1].reshape(28,28), cmap='Greys', interpolation='nearest')
plt.title(str(data.train.labels[1])) # anotação do dígito
plt.show()

Definindo os hiper-parâmetros
Tudo parece OK com os nossos dados. Podemos então começar a construção da rede neural. O primeiro passo é definir os hiper-parâmetros do modelo. Diferentemente dos parâmetros da rede, os \(w\), os hiper-parâmetros não são naturalmente aprendidos durante o treinamento e devem ser ajustados à mão. Alguns dos hiper-parâmetros mais importantes da rede neural são o número de camadas e o número de neurônios em cada camada. Esses hiper-parâmetros definem a capacidade da rede neural e, por meio deles, podemos ajustar o trade-off entre erro por viés e por variância. Quanto maior o número de neurônios, mais potente será a rede neural, mas a probabilidade dela sofrer com sobre-ajustamento será superior.
Outros hiper-parâmetros da rede neural são o tamanho do punhado de dados usado durante a otimização e o tamanho do passo dado a cada iteração de treino. Em outras palavras, o tamanho do punhado de dados define quão precisa será nossa estimativa local da superfície de custo, enquanto que a taxa de aprendizado definirá o tamanho do passo em cada descida nessa superfície de custo.
Outro detalhe importante é que a rede neural que vamos construir não tem apenas um neurônio na camada de saída, mas 10 neurônios. Cada neurônio representará a probabilidade da imagem conter um dos dígitos de 0 a 9.
# definindo constantes
lr = 0.01 # taxa de aprendizado
n_iter = 1000 # número de iterações de treino
batch_size = 128 # qtd. de imagens no punhado de dados
n_inputs = 28 * 28 # número de variáveis (pixeis)
n_l1 = 512 # número de neurônios da primeira camada
n_l2 = 512 # número de neurônios da segunda camada
n_outputs = 10 # número de neurônios da camada de saída
Nossa rede neural terá duas camadas, cada uma com 512 neurônios.
Construindo a rede neural
Felizmente, não precisamos construir uma rede neural do zero. Como elas são extremamente populares, outras pessoas já as deixaram pré-montada para facilitar nossa vida. A única coisa que precisamos fazer é dizer quais serão os hiper-parâmetros da rede neural, que o pacote TensorFlow construirá para nós.
O primeiro passo é converter os dados para um formato com que TensorFlow consiga trabalhar facilmente. Isso é feito com o comando tf.contrib.learn.infer_real_valued_columns_from_input(...) e passamos como argumento desse comando as imagens de treino. Por fim, transmitimos os hiper-parâmetros definidos acima para o comando DNNClassifier(...), o que cria a nossa rede neural e a armazena em deep_ann.
# converte os dados
x_input = tf.contrib.learn.infer_real_valued_columns_from_input(data.train.images)
# cria a rede neural
deep_ann = DNNClassifier(hidden_units = [n_l1, n_l2], # qtd. de neurônios por camada
feature_columns = x_input, # camada de entrada (dados)
n_classes = n_outputs, # número de classes (10 dígitos)
activation_fn = tf.nn.relu, # função de ativação das camadas
optimizer = tf.train.AdamOptimizer(learning_rate=lr)) # otimizador
OBS: Ao rodar esse código, talvez você veja alguns textos de aviso. Apenas os ignore. Nesses casos, o TensorFlow está nos fornecendo mais informação do que precisamos.
Treinando e Avaliando a RNA
Para treinar a rede neural criada acima basta um único comando do TensorFlow. Esse comando vem com o nosso modelo de rede neural e podemos acessá-lo com a notação de ponto a partir da rede neural criada acima: deep_ann.fit(...). Passamos ao comando as imagens de treino com os respectivos dígitos anotados. Lembre-se que esse é um problema de aprendizado de máquina supervisionado e que a tarefa da rede neural é aprender como mapear dos valores numéricos dos pixeis no dígito que está escrito na imagem. Por isso, precisamos passar também as anotações das imagens de treino: data.train.labels. Antes de encaminhar esses dados à rede neural, precisamos convertê-los para os tipos aceitos pelo modelo. As imagens devem ser do tipo float32 (dígitos com casas decimais), enquanto que as anotações devem ser do tipo int64 (dígitos inteiros, sem casas decimais). Por fim, passamos para o comando de treinamento o número de iterações de treino (passos na caminhada para baixo na superfície de custo).
deep_ann.fit(x=data.train.images.astype(np.float32), # conversão de tipo
y=data.train.labels.astype(np.int64), # conversão de tipo
batch_size=batch_size, # tamanho do punhado de dados
steps=n_iter) # iterações de treino
Após treinada, precisamos avaliar nossa rede neural nos dados de teste. Para isso, usamos o comando .evaluate, que pode ser acessado uma vez que a rede neural for treinada. Enviamos os dados e anotações de teste para esse comando e observamos a acurácia da rede neural, isto é, a taxa de acerto.
deep_ann.evaluate(data.test.images.astype(np.float32), # variáveis independentes
data.test.labels.astype(np.int64)) # variáveis dependentes
{'accuracy': 0.96030003, 'global_step': 1000, 'loss': 0.14502561}
Com apenas 1000 iterações de treino, nossa simples rede neural já consegue uma taxa de acerto de 96%. Isso não é um resultado muito bom, mas já é satisfatório, principalmente se considerarmos quão simples foi treinar esse modelo.
Próximos Passos
Como já disse, este post é bastante introdutório e tem o propósito de simplesmente instigar a curiosidade sobre aprendizado de máquina. Dentre tópicos que não podemos abarcar em um post introdutório estão outras arquiteturas de redes neurais (convolucionais, recorrentes, autoencoders, deep-q, adversárias…), formas de acelerar o treinamento, técnicas de regularização para controlar o sobre-ajustamento, isso sem falar nas outras classes de modelos de aprendizado de máquina, como máquinas de suporte vetoriais, árvores de decisão, Bayes ingênuo, k-vizinhos mais próximos…
Além disso, mesmo em se tratando de redes neurais bem simples como a que treinamos, o nível de abstração desse post é demasiadamente elevado, isto é, não mostrei como construir cada camada de neurônios, como conectá-las nem como construir o algoritmo de treinamento. Embora você possa utilizar aprendizado de máquina sem se preocupar muito com esses detalhes mais mecânicos, conhecê-los é extremamente importante. Entender de fato o funcionamento dos modelos é condição fundamental para solucionar possíveis falhas no treinamento, para descobrir quais modelos utilizar em cada situação e até mesmo para criar novos modelos ou melhorias que possam contribuir para a ciência de aprendizado de máquina.
Termino com um apelo: não seja um cientista de dados que simplesmente tenta aplicar um modelo caixa preta atrás do outro, na esperança de que algum resolva seu problema. Isso não é aprendizado de máquina; é tentativa e erro. Se for estudar aprendizado de máquina, entenda BEM as ferramentas que você usa. Entenda a matemática e a mecânica de um algoritmo em seus mínimos detalhes. Se possível, implemente os modelos de aprendizado de máquina sem o auxílio de pacotes. E, por fim, detalhes são muito, muito, muito importantes! A eles que devemos parte do renascimento atual de IA, então não os deixe passar batido.
Não é difícil encontrar material gratuito e de qualidade na internet, mas também é fácil cair em armadilhas, aprendendo apenas IA em um nível intuitivo, sem se adentrar nos detalhes. Segue uma pequena lista de onde encontrar conteúdo de qualidade sobre aprendizado de máquina:
- Blogs
- {Quinhentos:Nove}: Sou suspeito para falar, mas acredito que meu blog tenha os melhores tutoriais em português sobre aprendizado de máquina. Em parte, eu o criei com o objetivo de corrigir algumas falhas que percebi nos outros blogs sobre AM. Percebi que o conteúdo deles ou eram simplesmente intuitivos, sem aprofundamento na matemática e na implementação dos modelos, ou eram muito técnicos. Por isso, comecei a criar tutoriais estruturados para conter uma explicação intuitiva da técnica explicada, seguida de uma explicação matemática mais aprofundada e terminando com uma implementação bem documentada. Além disso, eu frequentemente posto sobre meus trabalhos para que sirvam como exemplos de aplicações de aprendizado de máquina.
- Blog do LAMFO: O nosso blog é uma excelente fonte de tutoriais e exemplos de aplicações de aprendizado de máquina. O LAMFO é a primeira entidade acadêmica no Brasil a tratar de aprendizado de máquina dentro da grande área de ciências humanas (e até onde sei, ainda é a única que atua na área), então acho que posso dizer que somos autoridade nesse assunto.
- colah's blog: Esse é um dos melhores blogs que conheço sobre aprendizado de máquina. Infelizmente, o conteúdo é mais avançado e com pouco enfoque em questões práticas (aquele problema do qual falei sobre ser muito técnico).
- R2RT: É um blog excelente, tanto em termos de tutoriais quanto em termos de explicação técnica e matemática por detrás dos algoritmos ensinados. Infelizmente, já começa no nível avançado, sem uma progressão clara entre os tutoriais.
- Andrej Karpathy blog: Andrej Karpathy é um pesquisador extremamente inteligente e que escreve com uma simplicidade incrível para alguém do seu nível de conhecimento. Esse não é um blog sobre tutoriais, mas fala sobre assuntos muito interessantes em aprendizado de máquina, além de fornecer implementações detalhadas e bem documentadas sobre o assunto tratado.
Referências
Esse post abrange o conteúdo que ministrei em um workshop do LAMFO sobre redes neurais. A proposta dessa iniciativa era mostrar que é possível falar sobre inteligência artificial e aprendizado de máquina de maneira simples e intuitiva, sem pressupor nenhum conhecimento técnico de quem está começando a aprender. Você pode acessar os slides do workshop aqui. Todas as imagens foram retiradas da internet e assumi que estavam em domínio público. Caso encontre uma imagem sua e queira as devidas citações, favor entrar em contato.
Como de costume, fiz o upload de um notebook Jupyter com o código desenvolvido nesse post. Nesse notebook, código e explicação são intercalados, de forma que você pode acompanhar esse mesmo post ao mesmo tempo que executa os comandos em Python. Recomendo que você baixe o notebook e reveja esse tutorial de redes neurais por lá. Isso te dará mais confiança para generalizar o que ensinei aqui para outras situações. Também coloquei um exercício adicional lá, para quem quiser fixar o que vimos acima. O notebook está no meu GitHub