Coletando Dados da Web para Aprendizado de Máquina - Parte 1
Algoritmos de aprendizado de máquina dependem de dados para treiná-los. Para criar um algoritmo para analisar quais parlamentares gastam de forma exorbitante, por exemplo, você necessita extrair dados dessas despesas. Um algoritmo de recomendação de páginas do Facebook, necessita dos dados de quais páginas as pessoas já seguem. Outro exemplo seria um algoritmo de reconhecimento de imagem. Para esse algoritmo, seria necessário obter várias imagens daquilo que você deseja reconhecer.
Em certos casos, a complexidade para criação do modelo não se encontra na tecnologia utilizada, mas na obtenção dos dados. Segundo o Diretor do Centro de Análise Avançada do Escritório de Contabilidade do Governo dos EUA:
“Independente do objetivo, é necessário entender a qualidade dos dados que você possui. A qualidade determina quão confiáveis tais dados são para se tomar boas decisões.”
‘Regardless of the goals, it’s important to understand the quality of the data you have. The quality determines how much you can rely on the data to make good decisions.’
Não somente o tratamento dos dados é uma forma essencial para o futuro da Inteligência Artificial, como também a forma de obtê-los. O primeiro semestre de 2018 foi marcado por uma série de questionamentos entre o senado americano e Mark Zuckerberg, CEO do Facebook. Isso se deu por conta da exposição do uso dos dados pessoais de pelo menos 50 milhões de usuários da plataforma. Tais dados foram coletados por meio de um questionário do Facebook chamado “thisisyourdigitallife”. Esses dados foram coletados por uma empresa de Inteligência Artifical e Data Mining chamada Cambridge Analytica violando as políticas de uso do Facebook. Avaliando o conteúdo que os usuários publicavam e curtiam, eles foram capazes de fazer propagandas políticas de forma mais efetiva durante as eleições presidenciais dos Estados Unidos de 2016 e na votação do Brexit.
Para evitar problemas legais como esse, neste post e no próximo explicaremos como extrair os dados da Web sem ferir os interesses dos proprietários deles. Abordaremos os três principais métodos de obter dados:
-
- Lei de Acesso à Informação,
-
- API’s
-
- Web Scrapping.

1 - Lei de acesso a informação
A extração de dados nem sempre requer uma programação extensiva. No caso de sites e órgãos governamentais, a Lei de Acesso à Informação (Lei nº 12.527/2011) permite o acesso à dados com uma simples requisição formal.
Tal lei possibilita a qualquer pessoa, física ou jurídica, sem necessidade de apresentar motivo, o recebimento de informações públicas dos órgãos e entidades. A Lei vale para os três Poderes da União, Estados, Distrito Federal e Municípios, inclusive aos Tribunais de Conta e Ministério Público. Entidades privadas sem fins lucrativos também são obrigadas a dar publicidade a informações referentes ao recebimento e à destinação dos recursos públicos por elas recebidos.
Em pesquisas do LAMFO tal recurso já foi usado com sucesso. Caso o site não possua uma seção para contato para fazer a requisição, um email ao órgão detalhando quais dados devem ser disponibilizados pode solucionar o problema.

2 - API’s
Sites de maior porte e redes sociais geralmente disponibilizam API’s para acesso. As empresas ligadas ao Facebook (Facebook, Instagram, Messenger), por exemplo, possuem a Graph Api que disponibiliza informações específicas dos usuários.
Uma API é uma forma de tornar pública e acessível as informações de uma empresa. É um servidor que recebe requisições simples HTTP e retorna dados que a empresa possui. Isso é feito para facilitar a análise de informações da empresa ou até mesmo permitir que haja uma interação dos usuários. Um exemplo são os jogos que encontram seus amigos do Facebook. Esses jogos podem ter a permissão de acessar os seus amigos ou outras informações. Todas essas informações são extraídas por uma chamada HTTP e a API geralmente retorna essas informações no formato JSON. Pode parecer uma tarefa difícil, mas em algumas situações, essa requisição HTTP é só uma URL que pode ser digitada em um navegador e no navegador é exibido o JSON. É importante saber como trabalhar com API’s, pois facilita muito a extração de dados.
Tal disponibilidade de dados não é para qualquer uso. Toda API com dados relevantes possui uma página para acesso ao desenvolvedor. Geralmente, para acessar essa página é necessário um cadastro e durante o cadastro são apresentados os termos de uso legal dos dados disponíveis na rede. A Política de Privacidade que deve ser lido e aceito durante a criação de uma conta de desenvolvedor.
Dependendo da API podem existir custos para acessá-la. Algumas empresas até mesmo limitam por quantidade de acessos dentro de um certo período de tempo, como é o caso do OpenWeatherMap:

O acesso aos dados da API é feito por meio de requisições do tipo HTTP e o retorno dos dados pode ser no formato json, xml ou até mesmo texto puro. Para saber como enviar ou como receber as requisições feitas à API, na página de desenvolvedor pode ser encontrada a documentação dela.
A documentação e a Política de Privacidade são as partes fundamentais de uma API. No caso da Cambridge Analytica e do Facebook, o erro estava no descumprimento da Política de Privacidade e na exploração de uma falha de desenvolvimento da API. Tal falha foi corrigida pelo Facebook, mas isso não removeu as informações que a Cambridge Analytica já tinha coletado. Desde então, o Facebook tem feito mudanças limitando o acesso às informações do usuário. Além disso, uma nova política foi implantada que, caso o usuário não acesse o App/Jogo dentro de três meses, o acesso daquele App/Jogo à API do Facebook será cancelado.
Após o cadastro, você terá acesso à uma chave privada e única de identificação de desenvolvedor. Essa chave privada deverá ser enviada nas requisições HTTP. Sites como o any api reúnem uma diversidade de API’s e contém ferramentas para testá-las: https://any-api.com/
Executaremos um exemplo extraindo os dados climáticos do Open Weather Map. Para isso criaremos uma conta de desenvolvedor para obtermos a chave privada: https://home.openweathermap.org/users/sign_up
A criação de conta é simples, username, email e senha. Porém, como dito, a parte mais importante está na leitura da Política de Privacidade. A Política de Privacidade contém o contato da empresa, os seus dados que são coletados, como eles são coletados, como esses dados são usados: https://openweathermap.org/privacy-policy
Após a criação de conta, será perguntado para qual propósito os dados serão usados. Na aba API keys, você pode ver e gerenciar suas chaves privadas da API. Note que após a criação de uma nova chave, somente após 10 minutos ela terá efeito:

Na aba Billing Plans é possível ver o seu plano atual (gratuito) e modificar caso haja necessidade.

Na página /api é possível encontrar toda a documentação para a API de clima. Para esse exemplo buscamos os dados de 5 dias atrás, na página /forecast5 veremos a documentação para obtermos dados por meio da requisição HTTP.
Iremos utilizar uma API Key que o próprio openweathermap fornece como teste, mas o melhor é criar uma para sí:
b6907d289e10d714a6e88b30761fae22
Em nosso exemplo iremos buscar os dados da cidade de Campos do Jordão. Iremos buscar por ID da cidade. Tomamos a liberdade de já buscar o ID que é 6322174, mas na documentação que passamo acima é possível encontrar a lista de todos os ID’s de cidades, além de outras formas de buscar caso a cidade buscada não possua um ID - buscando por latitude e longitude por exemplo. Agora que temos as informações necessárias para executar a requisição poderíamos criar um código para buscar tudo e salvar em um banco de dados ou em um arquivo. No entanto, é bom saber como testar a requisição, pois nem sempre temos certeza se um erro que possa por ventura aparecer está em nosso código de captura ou em nossa requisição ou até mesmo se o erro está no servidor. Para isso iremos aprender como testar as requisições.
Testando requisições à API’s
Antes de criar um código que acesse uma API, é sempre bom testá-la para verificar se ela lhe trará os dados que você realmente quer. Uma forma simples para verificar a conexão com a API sem código é utilizar o programa Postman.

O Postman permite:
- Executar requisições HTTP dos diversos tipos (POST, GET, PUT, DELETE…) ;
- Enviar parâmetros no Header da requisição;
- Passar argumentos no Body da requisição;
- Passar argumentos na própria URL;
- Gerenciar a forma de autenticação (nenhuma, OAuth 1.0, OAuth 2.0…);
- Gerenciar a forma de cache da requisição;
- Executar testes nas requisições;
- Executar uma requisição de tempos em tempos para verificar a performance e o retorno.
Além disso tudo, é possível agrupar diversas requisições dentro de uma mesma Collection e essas requisições compartilham das mesmas variáveis que serão enviadas ao servidor.

Logo a esquerda ficam as collections. O painel central exibe a URL da requisição e o tipo dela (no caso é uma do tipo GET). Ao clicar em Params, podemos enviar parâmetros pela url por meio de chave e valor, tal como abaixo:
www.site.com/api.php?senha=123&usuario=usuario123


Logo abaixo da URL, é possível configurar os vários tipos de autorizações na aba Authorization. Essa configuração é muito usada quando se trabalha com API’s, pois como explicamos geralmente o acesso à uma API deve ser feito por um usuário. Nela é possível configurar o tipo de autenticação assim como preencher o usuário e senha.

Na aba Headers podemos enviar parâmetros no Header da requisição atribuindo os valores por meio de chave e valor.

A aba Body só está habilitada para requisições que enviam parâmetros o servidor (POST, PUT..). Nela é possível selecionar diversos tipos de formas de enviar dados ao servidor. A mais comum é o x-www-form-urlencoded, que são dados por chave e valor. É possível que mesmo que um servidor peça um JSON enviando os dados por chave e valor ele aceite. Caso não seja aceito, selecione a opção raw e selecione JSON (application/json). Com isso é possível escrever um JSON no campo para ser enviado. O campo form-data convencionalmente é usado para enviar arquivos (imagens, audios).

Assim que sua requisição estiver completa, clique no botão Send. Ela será enviada e mais abaixo dos parâmetros estará a resposta. Na resposta, o campo Body pode ser visto na forma Pretty, formatado com quebra de linha e tabulação, ou na forma raw, como ele é recebido sem tratamento. Na forma pretty, é possível selecionar a visualização nos seguintes tipos: JSON, XML, HTML, Text.
Por ser possível visualizar em HTML, vemos que podemos fazer uma requisição a qualquer site e obter o HTML daquela página. Isso é interessante de ser usado em conjunto com os testes e o monitoramento - execução de tempos em tempos de uma requisição. Dessa forma podemos saber se uma página saiu do ar.
Além do Body da resposta que o servidor enviou, é possível ver os Cookies, Headers, o tempo que demorou a execução, o tamanho da requisição e o status de retorno. Vemos que em nosso exemplo a requisição retornou o Status 200, que é um padrão da Internet para informar que a requisição foi bem sucedida. Nem sempre a requisição é bem sucedida. Para esses casos, o Status é extremamente importante para informar a razão do erro. Um Status de erro que era muito comum de ser exibido ao usuário era o 404 - Página não encontrada. Esse era um erro comum, mas cada número tem um significado diferente. Cada faixa de centena tem um significado[11]:
- 1xx - Trazem uma informação
- 2xx - Informam sucesso, sendo o 200 sucesso completo sem ressalvas
- 3xx - Informam um redirecionamento. Ex.: 301 - a página foi mudada para outra URL
- 4xx - Erros no cliente, em outras palavras, erro na requisição feita. Seja por falta de usuário e senha (401), envio de um formato de media que não é suportado (415) ou qualquer outro erro na requisição será notificado.
- 5xx - Erros no servidor. O servidor pode estar fora do ar (503) ou até mesmo ter ocorrido um erro de processamento da sua requisição (503)

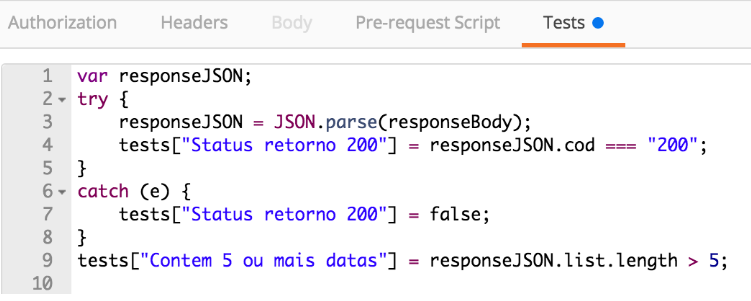
A aba de Tests foi deixada para ser tratada por último, pois ela é executada após o retorno da requisição. Nessa aba é possível escrever códigos em Javascript para testar o que veio de retorno, no lugar de ficar procurando no JSON se o retorno lhe interessa. Para criar um novo teste, preencha o valor de tests[‘nome do teste’] com o valor true para um teste que deu certo e false quando errado.

Após a execução da requisição, a aba Tests Results irá mostrar quantos e quais testes a requisição passou. Além disso ela indica quantos testes a requisição passou logo no nome da aba, para o exemplo, ela passou em todos os testes (3/3).
Voltando ao exemplo do openweathermap
Sabendo que temos os dados abaixo para executar a requisição, vamos realizar um teste utilizando o Postman

Além disso, vamos criar dois testes. Como o JSON de retorno contém o Status Code, vamos verificar se o Status é 200 criando o teste tests[“Status retorno 200”]. Caso a requisição falhe (e execute o catch) indicaremos que esse teste não passou atribuindo falso ao valor desse teste. O segundo teste verifica se o retorno contém mais de cinco datas com informações sobre o clima. Para este criaremos o teste tests[“Contem 5 ou mais datas”] e verificaremos se na lista de informações sobre o clima temos cinco ou mais elementos.
Ao executar nossa requisição, podemos ver o JSON retornado e verificar que a nossa requisição passou em ambos os testes (Test Results 2/2). Além disso, na imagem abaixo, conseguimos observar que a primeira data será um dia de céu limpo (clear sky).
Para saber mais do assunto
Caso seja do seu interesse se aprofundar no estudo de busca de dados por meio de API, temos alguns conteúdos a sugerir, assim como alguns links de referência. Para criar uma API, e disponibilizar os dados que você já tem para outras pessoas, sugerimos o uso da linguagem Node JS e o banco de dados Mongo DB. A criação de uma API por meio do Mongo é facilitada com a biblioteca Express. O banco de dados Mongo não é um banco de dados relacional. Apesar disso parecer um impedimento, na verdade é um facilitador, pois o Mongo é estruturado como um JSON. Isso facilita muito o trabalho de construção de uma API.
Para buscar dados por meio de uma API, sugerimos utilizar a linguagem Python. Não só pela facilidade, mas também por ser uma linguagem amplamente utilizada para a análise de dados. Sendo assim, não é necessário uma conversão, tudo é trabalhado na mesma linguagem. Recomendamos a leitura da documentação da biblioteca requests. Com ela conseguimos configurar tudo que fizemos no Postman. A documentação é bem elaborada e em português.
3 - Web Scraping
O web scraping é caracterizado pela captura de dados na web sem a utilização de uma API ou de um processo manual laborioso e tedioso. Todo o trabalho de acesso, captura e extração de dados é realizado por Bots, robôs que simulam o acesso de um usuário. Podemos capturar qualquer tipo de dado, não somente textos ou endereços web. É possível a captura de imagens, endereços residenciais, telefones, e-mails e etc., após a captura os dados podem ser diretamente inseridos em um banco de dados ou em arquivos.
Por quê fazer?
Como mostrado anteriormente o uso de APIs facilita e organiza a aquisição de dados, mas como apresentado por Ryan Mitchell em seu livro Web Scraping com Python, não é possível o uso de APIs quando [10]:
- Os conjuntos de sites não possuem uma API coesa;
- Os dados desejados pertencem a um conjunto finito e muito pequeno que o webmaster não achou necessário criar uma API para sua extração;
- A origem não tem infraestrutura ou habilidade técnica para desenvolvimento de uma API. Muitas APIs também contam com limitadores de velocidade ou cotas de requisições por IP, ou seja, dependendo de seu objetivo as APIs sozinhas não forneceram a quantidade ideal de dados, ou no tempo ótimo. E é aí que vemos o Web Scraping esperando calmamente pelo momento de fazer sua mágica, porque se você consegue acessar uma página no seu navegador, você consegue acessa-lá com um robô.

Quando uma API é disponibilizada, basta que o desenvolvedor siga a documentação e a política de privacidade para que se estabeleça um bom relacionamento entre robô e servidor.
Primeiro o essencial
Uma ponto importante para a boa convivência entre robô e servidor é a utilização do Protocolo de Exclusão de Robôs. Este protocolo é um método utilizado pelos administradores de páginas web para informar aos robôs que visitam a acessam quais os diretórios podem ou não ser vasculhados, e quais robôs podem acessar os diretórios.
Robots.txt. O começo!
A primeira coisa a ser feita pelos robôs é o acesso ao arquivo robots.txt que por convenção fica na pasta raiz da página, como por exemplo https://www.google.com/robots.txt.

No exemplo acima, ele diz a todos os robôs(User-agent: *) quais páginas podem (Allow) ser acessadas e quais não(Disallow).
Características essenciais do arquivo[11]: Arquivo de texto ASCII ou UTF-8(Não utilize programas de processamento de texto como Word ou LibreOffice);
- Nome Robots.txt é obrigatório;
- Somente 1 arquivo por página web;
- O arquivo pode ser aplicado em subdomínios ou em portas.
Exemplos:
A. Três diretórios são excluídos a todos os robôs.

B. Excluindo todos os robôs de todo o servidor:

C. Excluindo um robô específico

D. Permitir apenas um robô(ou seja, permite um e não permite nenhum outro):

E. Não permitir acesso a arquivos específicos:

O arquivo possui sintaxe simples para ser facilmente analisado. É muito importante frisar que o mostrado acima é um arquivo que indica o que pode ser acessado ou não, ele *não é um programa que analisa os robôs na página. Isso quer dizer que você pode fazer o scraping da página sem consulta-lo, mas sem fazer isso seu robô pode acabar acessando páginas protegidas, e pode fazer com que o webmaster o coloque como possível ameaça e bloqueie o acesso de seu robô em qualquer página do servidor. Resumindo, robots.txt não foi criado com o intuito de ser um controle de acesso. A segurança deve ser feita pelo administrador do servidor, bloqueie as pastas e arquivos que não devem ser listados, não os referencie no arquivo. Lá só deve aparecer o que pode ser acessado e quem pode acessar.
Conclusão
Buscamos através deste post apresentar algumas das formas mais frequentes de aquisição de dados. Neste primeiro momento foi apresentado um projeto completo de aquisição de dados utilizando API’s. Introduzimos algumas justificativas e informações básicas de uso e regras de boa convivência entre robôs e servidores, através do arquivo robots.txt e sua sintaxe. No próximo post desenvolveremos um robô para captura dos dados em páginas da web que não possuem APIs.