Sistemas de Recomendação usando Collaborative Filtering
Técnicas de Collaborative Filtering, ou Filtragem Colaborativa, exploram a ideia de que existem relações entre os produtos e os interesses das pessoas. Muitos sistemas de recomendação usam o Collaborative Filtering para entender essas relações e para dar uma precisa recomendação de um produto que o usuário pode gostar ou mesmo desfrutar.
Para isso filtragem colaborativa baseia esses relacionamentos nas escolhas que um usuário faz ao comprar, assistir, ou curtir alguma coisa. Em seguida, faz conexões com outros usuários de interesses semelhantes para produzir uma previsão.
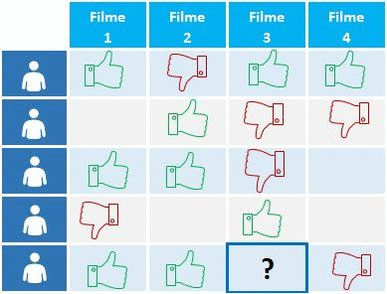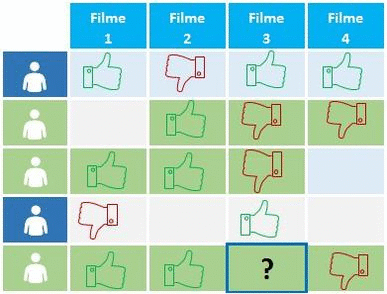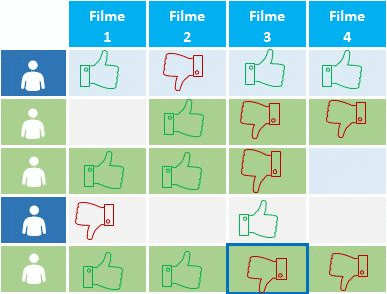
Cases de uso do Collaborative Filtering
Um exemplo popular de filtragem colaborativa é a do Netflix.
Tudo no site da empresa é dirigido pelas seleções do cliente que gera uma enorme base de dados, o qual é usada para ser transformada em recomendações para o cliente. Isso faz com que 75% a 80% do que é assistido no site provenha das recomendações ao invés da busca. Tanto que se especula que futuramente só irá sugerir de 3 a 4 filmes ao usuário, sendo que esses serão exatamente aqueles que ele possa quer assistir.
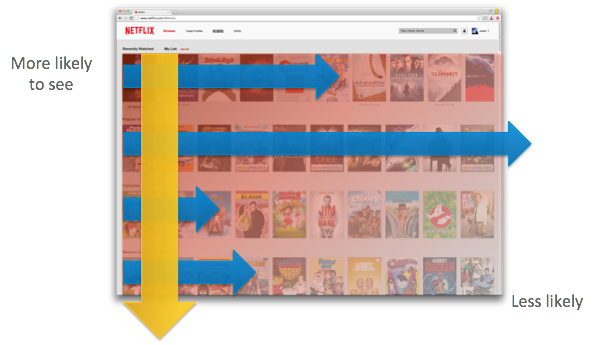
A Netflix ordena essas recomendações, em tal maneira que os itens melhores ranqueados são os mais visíveis para os usuários, na esperança de serem esses os selecionados pelo cliente. A mesma estratégia é usada para definir qual tipo de thumbnail irá ser apresentado ao cliente baseado em suas preferências, ou seja, em imagens de atores ou de cenas do filme.
A empresa julga que isso é tão estratégico que promoveram o Netflix Prize, uma competição aberta a todos e que tinha como objetivo desenvolver o melhor algoritmo para prever notas de usuários em filmes. Diversos algoritmos surgiram com essa competição e a equipe vencedora recebeu um prêmio de 1 milhão de dólares por melhorar as recomendações da Netflix em 10,06%.
A Amazon é outra grande referência em se tratando varejo digital e possui um sistema de recomendação de produtos muito poderoso e reconhecido no mercado. Esse sistema é um dos responsáveis pela alta conversão do site (transações dividido por visitas) que já chegou a ser de 10% e se baseia em diversas fontes de dados, tais como: produtos comprados pelo usuário, quais itens estão no carrinho de compras virtual, itens curtidos ou avaliados, o que outros consumidores viram ou compraram, o que você comprou anteriormente, bem como a frequência com que você olhou determinados livros ou mesmo outros itens durante a navegação ao seu site.
O site da Amazon é completamente personalizado de acordo com o cliente e conforme se navega e interage com o site, os produtos exibidos se alteram. Uma das recomendações utilizadas é o Item-to-Item Collaborative Filtering que é descrito no artigo e por ser de fácil implementação, pode ser utilizado por qualquer tipo de site.

A vantagem de usar o Collaborative Filtering é que os usuários têm uma exposição mais ampla a muitos produtos diferentes podendo estar interessados em alguns deles.
Essa exposição encoraja os usuários a continuarem o uso ou compra do produto. Isso não apenas proporciona uma experiência melhor para ele, como também beneficia o provedor de serviços com maior receita potencial e melhor segurança para seus consumidores.
Collaborative Filtering Tradicional
Dentro de vários modelos de Collaborative Filtering, o tradicional representa um cliente como um vetor N-dimensional de itens, o qual N é o número de itens de catálogo distinto. Os componentes do vetor são positivos para itens comprados ou com classificação positiva. E negativos para itens com classificação negativa. Para compensar itens mais vendidos, o modelo normalmente multiplica os componentes do vetor pela freqüência inversa (o inverso do número de clientes que compraram ou avaliaram o item), tornando os itens menos conhecidos mais relevantes. Além disso, ele gera recomendações com base em alguns clientes que são mais parecidos com o usuário. Por fim, a similaridade de dois clientes A e B pode ser avaliada de várias maneiras. Uma delas é medir o cosseno do ângulo entre os dois vetores:
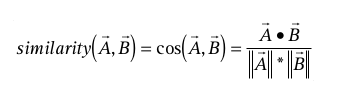
Onde “•” denota o produto escalar dos dois vetores sobre a normalização dos vetores. Por exemplo:
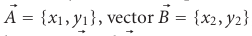
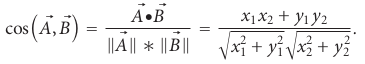
Em uma situação real, diferentes usuários podem usar diferentes escalas de classificação, o qual a semelhança de cosseno vetorial não levará em conta. Para resolver esse problema, a similaridade de cosseno ajustada é usada ao subtrair a média do usuário correspondente de cada par co-avaliado. A semelhança cosseno ajustada tem a mesma fórmula que a Coeficiente de Correlação de Pearson.
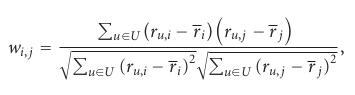
Na verdade, correlação Pearson executa semelhança de cosseno com uma normalização das avaliações do usuário de acordo com a sua próprio comportamento de classificação. Assim, pode-se obter valores negativos com a correlação de Pearson, levando em conta a escala de classificação de n pontos.
Alguns desafios com Collaborative Filtering
Um deles é o Data Sparsity:
Ter um conjunto de dados grande provavelmente resultará em uma matriz de item/usuário grandes e esparsas, que pode fornecer um bom nível de acurácia, mas também representam um risco para a performance. Em comparação, ter um pequeno conjunto de dados pode resultar em velocidades mais rápidas de respostas, porém menor acurácia das recomendações.
Outra questão a ter em mente é algo chamado de “Cold Start”:
Isso acontece quando os novos usuários ou itens não têm um número de quantidade suficiente de avaliações para dar uma recomendação precisa. Novos itens não podem ser recomendados até que alguns usuários os classifiquem e novos usuários são improváveis, dadas a falta de sua classificação ou histórico de compras.
A escalabilidade também pode se tornar um problema uma vez que a medida que o número de usuários aumenta e a quantidade de dados expande-se. Dessa forma, algoritmos de filtragem colaborativa vão começar a sofrer quedas no desempenho devido ao aumento do volume.
Os “Sinônimos” refere-se à frequência de itens semelhantes, porém rotulados de forma diferentemente espacialmente com sinônimos regionais. Um exemplo disso seria “Penal” vs ‘Estojo’.
Um sistema de recomendação pode tratar esses dois itens de forma diferente por causa de sua rotulagem embora, funcionalmente, sejam muito semelhantes um para o outro.
O termo ‘Gray Sheep’ refere-se aos usuários que têm opiniões que não necessariamente vão se ‘encaixar’ ou são semelhantes a qualquer grupo específico. Esses usuários não concordam ou discordam consistentemente em produtos ou itens, portanto, receberão recomendações não muito assertivas para eles.
Em um sistema de recomendação, os usuários podem avaliar produtos que eles gostam ou não gostam e é isso que o Collaborative Filtering usa para determinar boas recomendações. No entanto, Shilling Attacks são o abuso desse sistema classificando certos produtos muito positivamente e/ou outros produtos negativamente independentemente da opinião pessoal. Permitindo que esse produto seja recomendado mais frequentemente.
Em alguns sistemas de recomendação, existem falta de diversidade para recomendações. Isso ocorre porque itens populares são recomendados mais frequentemente, pois mais usuários os usam e classificam. Por isso é fácil imaginar que um item popular consegue uma maior quantidade de avaliações. Essas classificações representam informações que são usadas pelo sistema, que por sua vez, cria outras recomendações para outros usuários. Dessa forma, há mais usuários que irão usar, assistir e comprar esses produtos, tornando-os mais populares.
Isso cria um ciclo em que novos itens são apenas uma sombra por trás dos itens populares resultantes na falta de diversidade. Esse fenômeno é conhecido como efeito ‘Long Tail’.
Algoritmos de Machine Learning
Além das abordagens usando Similaridade de Coseno ou mesmo Correlação de Pearson, que são baseados em operações aritméticas, podemos desenvolver a filtragem colaborativa usando alguns algoritmos de Machine Learning tais como:
Algoritmos baseados em Clusterização (KNN): A ideia da clusterização é a mesma dos sistemas de recomendação baseados em memória. Em algoritmos baseados em memória, usamos as semelhanças entre usuários e/ou itens e os usamos como pesos para prever uma classificação para um usuário e/ou um item. A diferença é que as semelhanças nessa abordagem são calculadas com base em um modelo de aprendizado não supervisionado, em vez de Correlação de Pearson ou semelhança de cosseno. Nesta abordagem, também limitamos o número de usuários semelhantes como k, o que torna o sistema mais escalável.
Deep Learning (CNN/RNN): DL é um campo de Machine Learning que permite modelos computacionais compostos por várias camadas de processamento de representação e abstração que ajudam a compreender dados como imagens, sons e textos. Esses métodos melhoraram drasticamente o estado da arte em visão computacional, reconhecimento de voz, processamento de linguagem natural (NLP) e muitos outros domínios, como descoberta de drogas e detecção de células cancerígenas. Um exemplo é a biblioteca Fast.AI que pode dar uma grande acurácia e possui uma relativa facilidade de implementação.
Conclusão
Sistemas de Recomendação, mais especificamente o método de Filtragem Colaborativa, é um tema que demanda grande atenção no cenário atual mercadológico. Este método pode apresentar acurácia elevada, mesmo sendo de fácil implementação. Seu principal objetivo é fazer previsões sobre os interesses de um usuário com base nas preferências de outros usuários que tenham um padrão de comportamento semelhante. Dessa forma, recomenda um produto e/ou serviço para garantir o sucesso no volume de conversão de vendas e no engajamento do serviço.
Referências:
CARLOS A. GOMEZ-URIBE and NEIL HUNT, Netflix, Inc. The Netflix Recommender System: Algorithms, Business Value, and Innovation
SHAPIRA Bracha KANTOR Paul B. RICCI Francesco, ROKACH Lior. Recommender Systems Handbook. Springer, 2011
YORK Jeremy LINDEN Greg, SMITH Brent. Amazon.com recommendations item-to-item collaborative filtering.
Xiaoyuan Su and Taghi M. Khoshgoftaar. Review Article - A Survey of Collaborative Filtering Techniques
Como funciona o sistema de recomendações da Netflix. Disponível em: https://help.netflix.com/pt/node/100639. Acesso em: 01 de setembro de 2018;
A Global Approach to Recommendations. Disponível em: https://media.netflix.com/en/company-blog/a-global-approach-to-recommendations. Acesso em: 01 de setembro de 2018;
The Netflix Tech Blog Disponível em: https://media.netflix.com/en/company-blog/a-global-approach-to-recommendations. Acesso em: 01 de setembro de 2018;
Netflix may only give you 3 or 4 recommendations in the future. Disponível em: https://www.huffpostbrasil.com/entry/netflix-recommendations_n_5357619. Acesso em: 01 de setembro de 2018;
Amazon’s recommendation secret. Disponível em: http://fortune.com/2012/07/30/. Acesso em: 01 de setembro de 2018;
Collaborative Filtering. - Big Ddata University Disponível em: http://www.bigdatauniversity.com.br. Acesso em: 01 de setembro de 2018;
Aula Aberta - Lecture 43 — Collaborative Filtering | Stanford University – Leskovec, Rajaraman, and Ulman. Disponível em: https://www.youtube.com/watch?v=h9gpufJFF-0. Acesso em: 01 de setembro de 2018;