Pay Attention - Explicando o Mecanismo de Atenção
Uma das aplicações mais relevantes atualmente em aprendizado de máquina é a tradução por máquina (machine translation, MT). O seu objetivo é traduzir uma frase de uma linguagem para outra. Um dos principais desafios dessa técnica é que muitas vezes a frase original e a frase traduzida não têm o mesmo número de palavras. Além disso, o modelo precisa generalizar os padrões da linguagem utilizando apenas uma pequena fração de exemplos traduzidos (o número de possíveis frases em uma linguagem é enorme).
As Redes Neurais Recorrentes (RNR) obtiveram bastante sucesso ultimamente para tratar dados sequenciais, como texto (tradução), áudio (identificação de fala) e séries temporais (predição). Modelos sequência-para-sequência (abreviado como seq2seq, do inglês sequence to sequence) são uma classe especial de arquitetura das RNR. Eles são usados para resolver problemas complexos como tradução, chat-bots e resumo de textos.
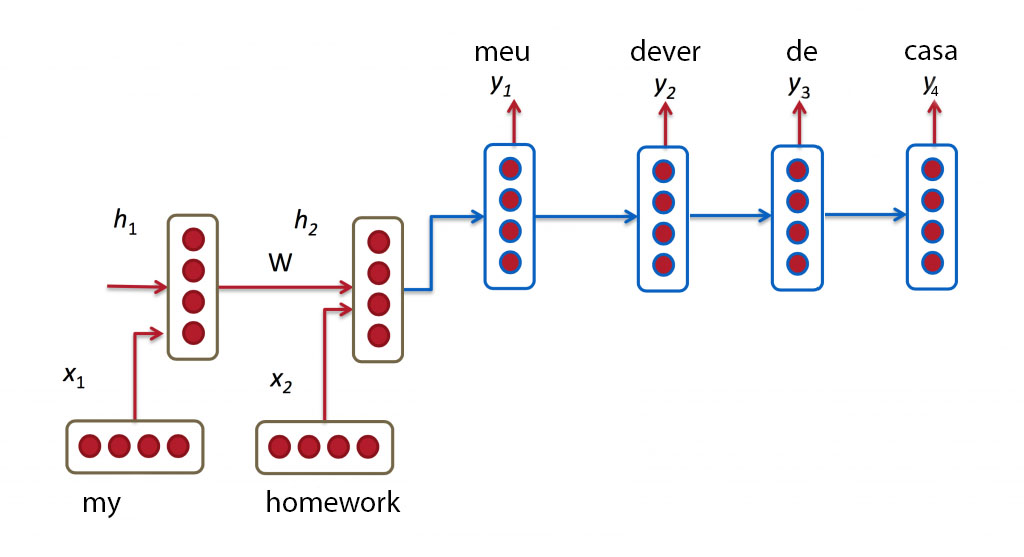 Adaptado de http://www.wildml.com/2016/01/attention-and-memory-in-deep-learning-and-nlp/
Adaptado de http://www.wildml.com/2016/01/attention-and-memory-in-deep-learning-and-nlp/
Os modelos seq2seq normalmente são formados por uma arquitetura encoder-decoder, onde o encoder processa a sequência de entrada e comprime essa informação em um vetor de contexto de tamanho fixo (o último hidden state).
A imagem acima ilustra essa relação. As palavras “my” e “homework” servem de entrada para o encoder (não foi mostrado, mas há um sinal específico que serve representar o final e começo das sequências). O decoder então faz a tradução com base no h2.
Espera-se que esse seja uma boa representação da sequência de entrada, esse vetor é então “decodificado” e utilizado para gerar a sequência de saída. Esses modelos obtiveram resultados relevantes nos últimos anos, porém, eles possuem duas limitações que afetam seu desempenho: 1) As RNR usam um tamanho fixo para a representação da entrada e saída. Porém, em muitos casos, o tamanho da entrada e saída é diferente. Tome como exemplo a tradução inglês-português: “I did my homework yesterday” (5 palavras) vira “Eu fiz o meu dever de casa ontem” (7 palavras).
2) O uso de um vetor de sequência de tamanho fixo torna-se problemático para sequências de entrada longas, visto que o vetor de contexto deve considerar a informação de toda a sequência de entrada. Na tradução de uma frase longa, por exemplo, há grandes chances da primeira palavra de uma frase em inglês ser altamente correlacionada com a primeira palavra da respectiva tradução em português. Logo, o vetor de contexto teria de ser capaz de representar essa longa dependência no tempo.
O vetor de contexto é o gargalo em modelos como esse. Na teoria, algumas adaptações como o uso de LSTM (Long short-term memory) podem melhorar o desempenho mas isso ainda é um problema na prática.
O mecanismo de atenção surge para suprir essa limitação do vetor de contexto. Em vez de codificar toda a sequência de entrada em um vetor de contexto, o mecanismo de atenção permite o decoder “focar” em diferentes partes da sequência de entrada em cada etapa da geração da saída. Ou seja, o decoder utiliza todos os estados intermediários para gerar a saída.
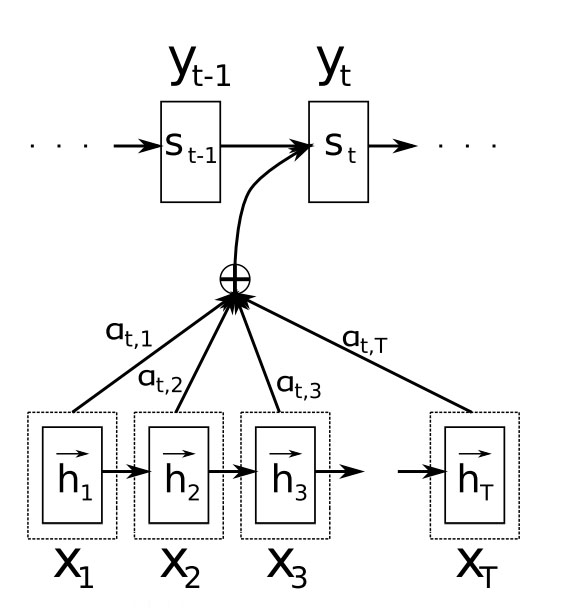 Adaptado de
Adaptado de
Neural Machine Translation by Jointly Learning to Align and Translate
A imagem acima representa o mecanismo de atenção, x é a sequência de entrada e y a de saída. É importante notar que agora a saída depende da combinação ponderada de todos os estados de entrada. Os a’s representam os pesos de atenção, ou seja, quanto cada estado de entrada é considerado em cada saída. Por exemplo, se \(a_{2,1}\) é um valor grande, isso significa que a primeira palavra de entrada é importante na geração da segunda palavra na saída.
Uma das vantagens de utilizar o mecanismo de atenção é a interpretabilidade. É possível saber qual parte da entrada foi mais relevante para cada parte da saída.
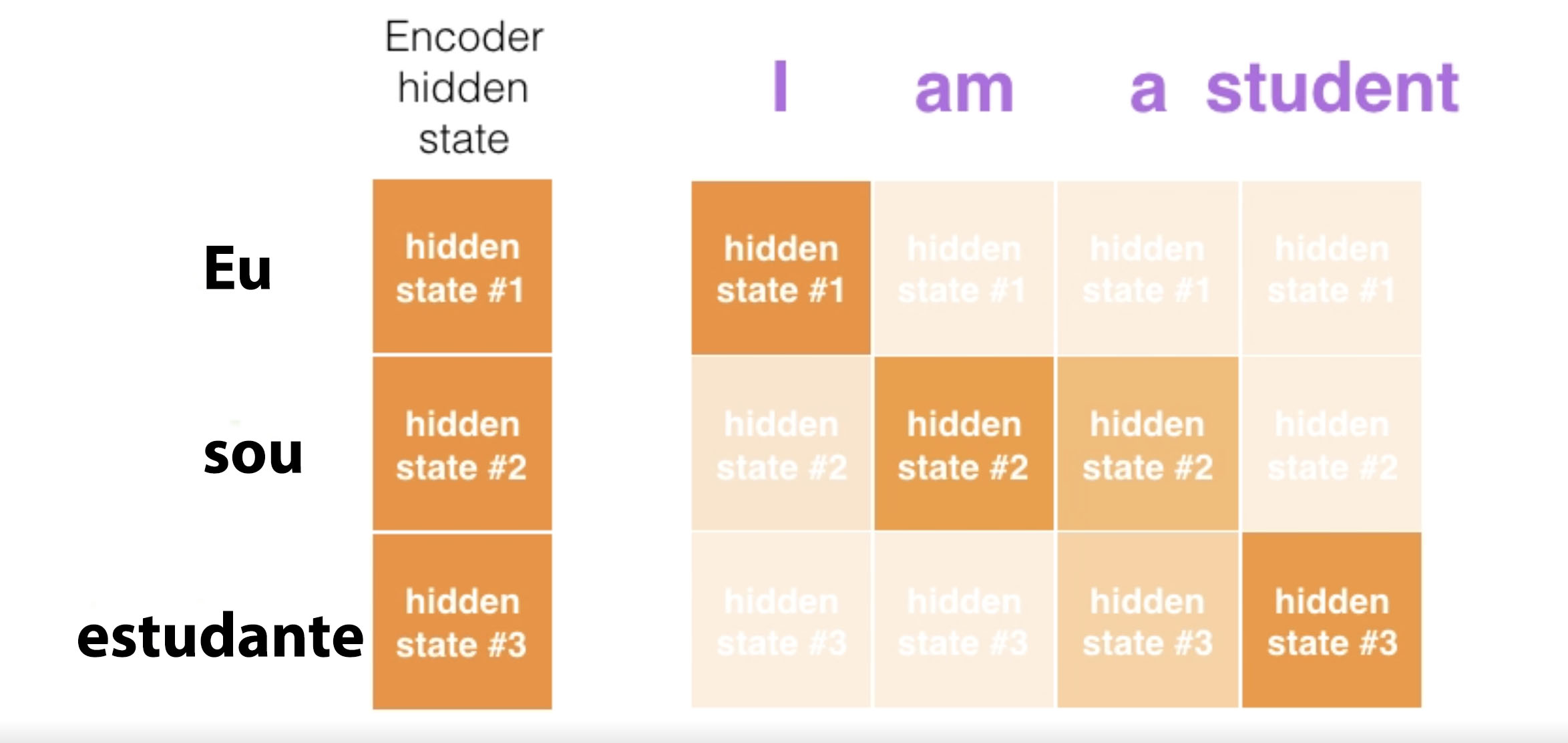 Adaptado de http://jalammar.github.io/visualizing-neural-machine-translation-mechanics-of-seq2seq-models-with-attention/
Adaptado de http://jalammar.github.io/visualizing-neural-machine-translation-mechanics-of-seq2seq-models-with-attention/
A imagem acima mostra a tradução da frase “eu sou estudante” para o inglês. Valores maiores de atenção são representados por cores mais escuras. Perceba que “eu” possui um peso grande para “I” assim como “estudante” possui para “student”.
Como o mecanismo de atenção funciona?
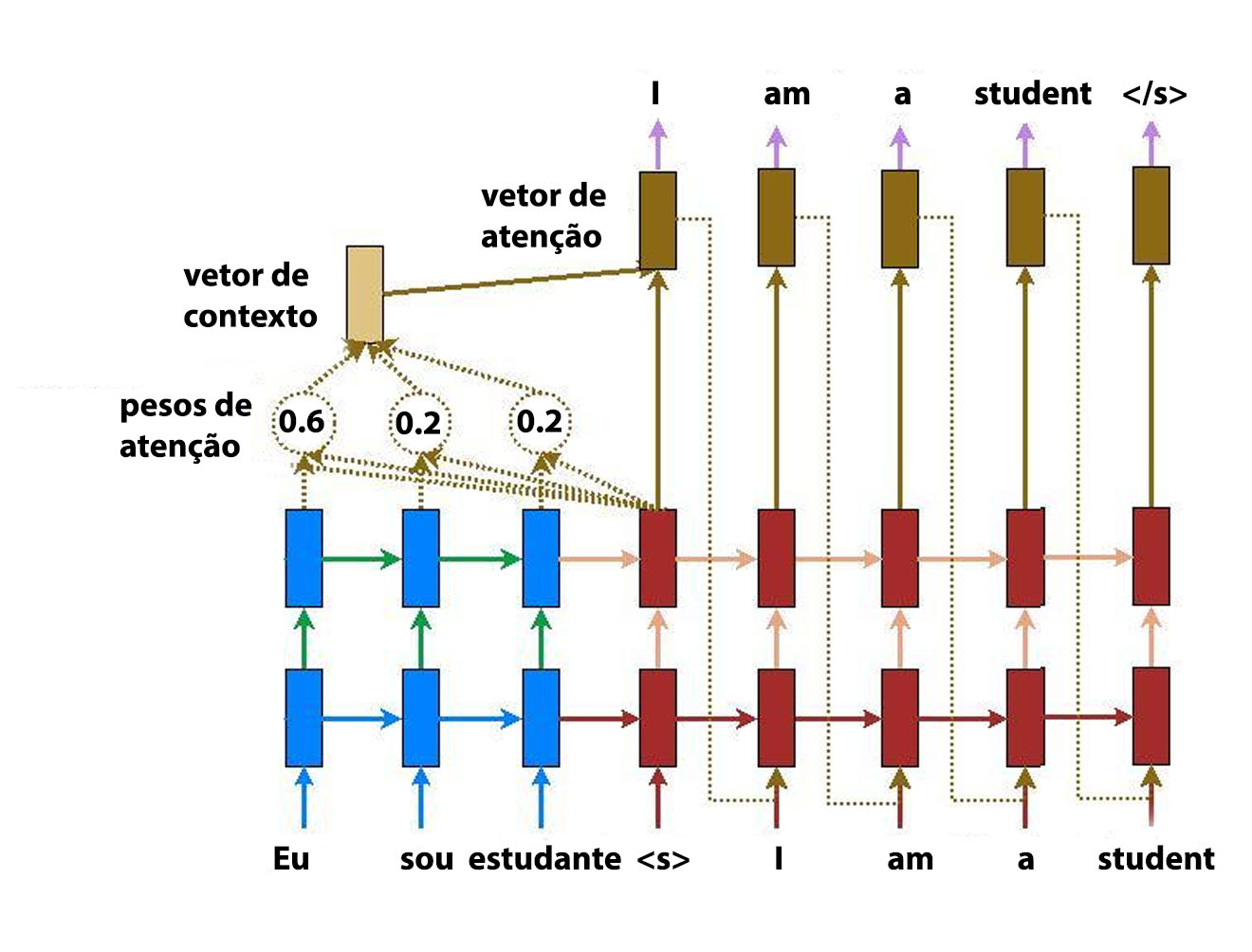 Adaptado de https://medium.com/syncedreview/a-brief-overview-of-attention-mechanism-13c578ba9129
Adaptado de https://medium.com/syncedreview/a-brief-overview-of-attention-mechanism-13c578ba9129
A arquitetura é similar ao encoder-decoder básico, com uma particularidade entre o encoder (azul) e o decoder (vermelho) representados na imagem acima. A diferença principal em relação aos outros modelos seq2seq é o vetor de contexto que considera todo os elementos da entrada. Cada elemento da saída considera o respectivo vetor de contexto e a saída no instante de tempo anterior. A atenção é definida pelas três equações abaixo:
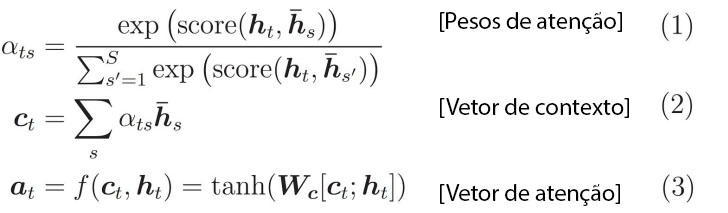
O score na equação (1) é normalmente uma rede neural simples, os pesos de atenção são normalizados usando softmax em relação ao input. O vetor de contexto é calculado pela soma ponderada dos hidden states em relação aos seus pesos. Esse vetor é calculado para cada palavra na saída. Se considerarmos todos os pesos de atenção, teremos uma matriz de dimensões N x M, onde N é o tamanho do input e M o tamanho do output. Por último, o modelo utiliza o vetor de contexto e o hidden state para determinar a saída. A equação (3) mostra a tanh como a não linearidade mas pode-se usar outras funções, como ReLU.
Atenção além da tradução
O mecanismo de atenção nesse post foi introduzido utilizando sua aplicação na tradução. Porém, esse método também é utilizado em outras aplicações. Em Show,Attend and Tell, o mecanismo de atenção foi aplicado para gerar descrição de imagens. A descrição era gerada por uma RNR com atenção após receber a representação da imagem feito por uma Rede Neural Convolucional.
 Fonte :
Fonte :
Show,Attend and Tell
A parte mais clara das imagens representa maior peso e a imagem sublinhada mostra de qual palavra os pesos são. É possível notar que o modelo identificou de forma correta os exemplos de acordo com a distribuição dos pesos.
Conclusões
O mecanismo de atenção surge como solução para a dificuldade de representar longas sequências em modelos convencionais. Um dos lados negativos dessa abordagem é o custo computacional, visto que é preciso calcular os pesos para cada componente da saída, o que pode tornar o custo computacional razoavelmente alto.
Referências:
Attention and Memory in Deep Learning and NLP http://www.wildml.com/2016/01/attention-and-memory-in-deep-learning-and-nlp/
A Brief Overview of Attention Mechanism https://medium.com/syncedreview/a-brief-overview-of-attention-mechanism-13c578ba9129
Attention Based Machine Translation https://towardsdatascience.com/attention-based-neural-machine-translation-b5d129742e2c
Augmented RNNs https://distill.pub/2016/augmented-rnns/
Neural Machine Translation by Jointly Learning to Align and Translate