Random Forest
Random Forest é um método de aprendizado de máquina utilizado para problemas que envolvam classificação ou regressão. Ele se baseia em uma coleção de árvores de decisão em que os
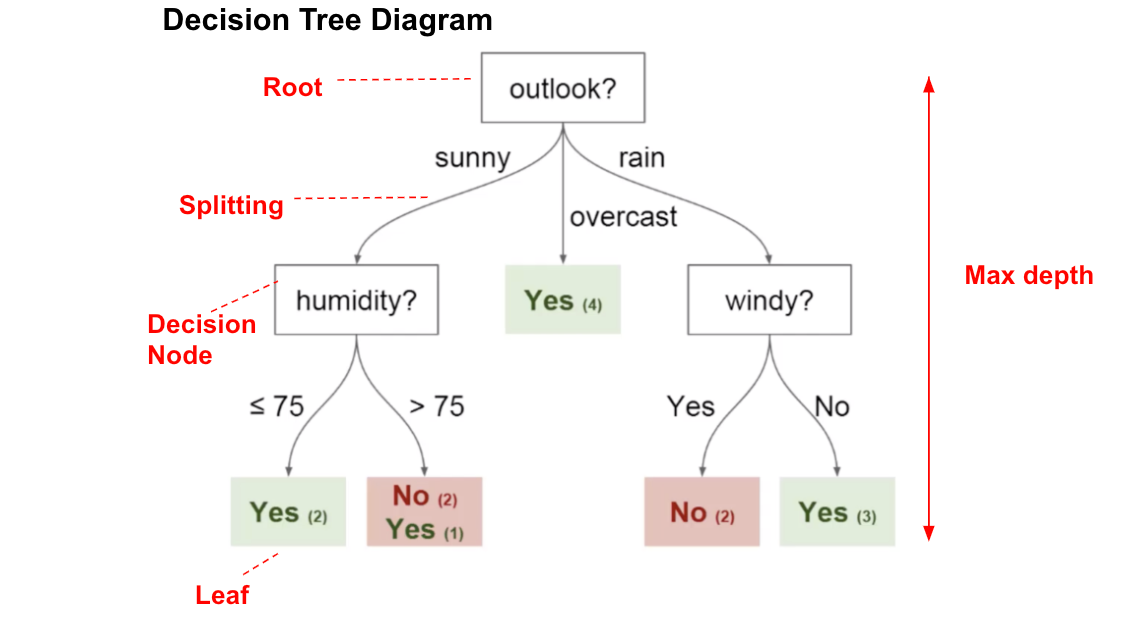
são vetores aleatórios independentes e identicamente distribuídos. Podemos pensar em uma árvore de decisão como uma representação gráfica para um determinado processo de decisão. As árvores são formadas por nós, que armazenam informação (perguntas). O nó raiz é o nó que possui maior nível hierárquico e, a partir dele, ramificam-se os nós filhos. O nó que não possui filhos é conhecido como nó folha ou terminal. A imagem abaixo exemplifica a estrutura de uma árvore.
e representa a probabilidade de se classificar incorretamente uma amostra retirada aleatoriamente se esta fosse aleatoriamente classificada de acordo com a distribuição de classe dos dados. A Entropia mede a desordem de um grupamento de variáveis e é dada por
Por fim, para o MAE e o MSE, tem-se que
Importante notar que com relação as duas últimas, o MSE coloca mais peso em grandes erros, isto é, coloca mais importância a erros maiores do que a MAE. De modo que se para o problema em questão, um erro de (10-5) tem que ser analisado como um erro maior que 5, é melhor utilizar o MSE como critério. Mas caso a disparidade não tenha tanta importância no problema, então pode-se utiizar o MAE. A ideia de *Random Forest* reside na junção de muitas árvores de decisão que, a partir de critérios de seleção, se ramificam e chegam cada uma a uma resposta para o problema. Em seguida, a resposta que tiver mais voto é a solução geral. Portanto, cada árvore gera um voto unitário para a classe mais popular dos dados de entrada $x$. O modelo como um todo é formado por árvores de decisão que crescem a partir dos dados de entrada. Para que as árvores não tenham alta correlação, pois isso diminuiria o poder de generalização do modelo, alguns métodos são aplicados. O *Bootstrap Aggregation* ou *Bagging* consiste em uma metodologia de amostragem aleatória para substituir as combinações de entrada dos dados de treinamento. De maneira mais informal, o *Bagging* faz com que cada árvore retire aleatóriamente uma amostra (com reposição) mantendo o tamanho original dos dados. Com o *Feature Randomness*, cada árvore possui um sub conjunto aleatório de features para serem escolhidos. Dessa forma, existe uma maior variabilidade entre as árvores, o que resulta em uma menor correlação entre elas. Há duas razões principais para o uso desses métodos em *Random Forest*, em primeiro lugar eles aumentam a acurácia dos resultados diminuindo a correlação de cada árvore e, além disso, fornecem estimativas dos erros de generalização das árvores de forma contínua. Em suma, *Random Forest* é um algoritmo utilizado para classificação e regressão que consiste em diversas árvores de decisão. Utiliza métodos como Bagging e Feature Randomness para construir suas árvores, e assim, criar uma floresta com baixa correlação. Utiliza a ideia de que a decisão por voto para a previsão final é melhor do que a previsão individual de cada árvore. Para demonstrar a capacidade do modelo de generalização, é necessário entender a função margem do modelo, que consiste em medir o nível em que o número médio de votos da classificação para a classe certa de $X$, sendo $Y, X$ um conjunto de treinamento, excede a classificação para outra classe. Dessa forma, dado um conjunto de classificadores
em que
É possível demonstrar que pela Lei Forte dos Grandes Números, que o erro de generalização converge para:
A principal mensagem da equação acima é a de que por mais que se aumente a quantidade de árvores, existe uma restrição para o erro de generalização, de modo a restringir também o *overfit*. Por fim, é importante ter em mente que o objetivo principal de *Random Forest* é minimizar o erro de generalização com a menor perda de dados. Isso mostra a dependência do modelo aos dados, de modo que, caso tenha-se *garbage in*, no fim terá *garbage out*. # Light Gradient Boosting Model O Algoritmo *Light Gradient Boosting Model*, mais conhecido como *LightGBM* faz parte da família de algoritmos de Gradient Boosting Decision Tree (GBDT), assim como os algoritmos *XGBoost* e *pGBRT*. GBDT são um grupo de modelos que tem sido muito utilizado em técnicas de Aprendizado de Máquina principalmente pelo surgimento de novos estudos na área de tecnologia e *big data* (KE et al, 2017). A lógica dos modelos *Gradient Boosting* é a junção de vários modelos "fracos", o processo de aprendizado vai se ajustando a medida que os modelos são adicionados e o objetivo é produzir uma estimativa mais precisa das variável resposta. Os modelos são construídos em etapas e em cada etapa, os modelos são correlacionados com um gradiente negativo da função de perda. A função de perda é uma medida de ajuste dos coeficientes do modelo e é utilizada para que nas etapa do *Gradient Boosting* os erros sejam minimizados(FRIEDMAN, 2001; NATEKIN;KNOLL, 2013). Algoritmos de GBDT utilizam da lógica de Aprendizado por Árvore de Decisão para modelagem preditiva e estes modelos precisam estudar todas as instâncias dos recursos (variáveis) para estimar qual seria o ganho de informação em cada nó de decisão. Isso mostra que a complexidade computacional destes modelos depende da quantidade de dados e dos recursos das bases de dados, logo os modelos com implementações muito demoradas devido ao uso de bases com muitos dados. A diferença principal dos outros modelos baseados em Árvore de Decisão é que, no LightGBM, as árvores crescem "verticalmente" enquanto os outros algoritmos crescem "horizontalmente". Crescer verticalmente significa que a Árvore cresce *leaf-wise*, ou seja, que o Algoritmo vai selecionar a ''folha'' que tenha o máximo *delta loss to grow*.  [Fonte](https://medium.com/@pushkarmandot/https-medium-com-pushkarmandot-what-is-lightgbm-how-to-implement-it-how-to-fine-tune-the-parameters-60347819b7fc) Na tentativa de solucionar os problemas de com tempo de processamento e o uso da memória, Ke et al (2017)propõe o uso de duas técnicas para aprimorar os algoritmos de *Gradient Boosting*: Amostragem unilateral baseado em Gradiente (*Gradient-based One-Side Sampling* - GOSS) e Pacote de Recursos Exclusivos (*Exclusive Feature Bundling* - EFB). Algoritmos de *Gradient Boosting* que utilizam GOSS e EFB são denominados de *Light Gradient Boosting Models*, ou LightGBM. Este modelo se tornou muito popular em estudos e em competições na plataforma de competições de Ciência de Dados [Kaggle](https://www.kaggle.com/), principalmente pela velocidade de processamento, menor uso de memória e melhor acurácia das previsões. A Amostragem unilateral baseado em Gradiente é utilizado dentro de um contexto que mostra que instâncias de dados com gradientes diferentes possuem desempenhos diferentes no ganho de informações. Isto significa que a instância com gradientes maiores, terão maior contribuição no ganho de informação, logo a amostragem focando nestas instância é benéfica para uma maior acurácia. Amostrasfem unilateral baseado em gradiente é uma técnica que vai focar nas instâncias de dados com gradientes maiores e eliminando aleatoriamente as instâncias com gradientes menores. O Pacote de Recursos Exclusivos é uma técnica que se faz necessária tendo em vista que, em aplicações reais, embora haja um grande número de *features*, o espaço de *features* é escasso. Muitas *features* dentro do espaço acabam sendo exclusivas, isto é, em poucas situações recebem valores diferentes de zero simultaneamente. O Pacote de Recursos Exclusivos faz parte de um algoritmo eficiente que seleciona as *features* exclusivos em uma única *feature* e assim auxiliar com o uso de menos memória no processamento. Estas técnicas fazem com que o LightGBM tenha uma maior velocidade de processamento, consiga lidar com grandes bases de dados, ocupe menos memória para executar e foque na acurácia dos resultados. Entretanto, o modelo é sensível a *overfitting* e, por isso, não é aconselhável de uso em bases com poucas observações # Implementação Básica dos Modelos Vamos fazer uma implementação breve dos modelos em Python e comparar o desempenho dos modelos. A base utilizada foi a "Breast Cancer Dataset" criada para o Women Coders' Bootcamp organizado pelo PNUD de Nepal e retirada do Kaggle. Ela possui 5 colunas com características de tumores (*features*) e uma coluna com o resultado. Cada coluna possui 569 dados. ## Random Forest Primeiro importamos os pacotes: ``` import numpy as np import pandas as pd from sklearn import preprocessing from sklearn import metrics from sklearn.model_selection import train_test_split, cross_val_score, cross_val_predict ``` Lemos o arquivo .csv contendo os dados e criamos o data frame: ``` data = pd.read_csv('breastcancer.csv') datas = pd.DataFrame(preprocessing.scale(data.iloc[:,1:32])) datas.columns = list(data.iloc[:,1:32].columns) datas['diagnosis'] = data['diagnosis'] ``` Estabelecemos as variáveis preditoras e a variável que queremos prever (*target*): ``` predictors = ['mean_texture', 'mean_perimeter', 'mean_area', 'mean_smoothness'] target = "diagnosis" X = datas[predictors] y = np.ravel(datas.loc[:, [target]]) ``` Agora separamos os dados em conjuntos de teste e treino, de modo a termos 20% dos dados separados para teste: ``` # Split the dataset in train and test: X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0) print('Shape of training set : %i || Shape of test set : %i' % (X_train.shape[0], X_test.shape[0])) ``` Inicializamos o modelo Random Forest Classifier do pacote *sklearn* e estabelecemos os parêmetros. O único parâmetro levemente otimizado foi o número de estimadores. Ao final, imprimimos a Acurácia e a Matriz de Confusão: ``` # Initiating the model: Random Forest Classifier from sklearn.ensemble import RandomForestClassifier rf = RandomForestClassifier(n_estimators=18, criterion="gini", max_depth=None, min_samples_split=2, min_samples_leaf=1, max_features="auto", bootstrap=True, random_state=0, max_samples=455, verbose=1) rf.fit(X_train, y_train) prediction = rf.predict(X_test) print('Accuracy:', round(metrics.accuracy_score(y_test, prediction), 4)) print('Confusion Matrix:\n', metrics.confusion_matrix(y_test, prediction)) ``` Os resultados do modelo são: ``` Acurácia: 0.9474 Matriz de Confusão: [[43 4] [ 2 65]] ``` Assim, obtivemos 43 verdadeiros positivos (*true positives*), 65 verdadeiros negativos (*true negatives*), 4 falso positivos (*false positives*) e 2 falso negativos (*false negatives*). E uma acurácia de 94,7% no modelo. ## LightGBM O modelo Light GBM foi exemplificado com o pacote *scikit-learn* utilizando os seguintes parâmetros. ``` import lightgbm as lgb d_train = lgb.Dataset(x_train, label=y_train) params = {} params['boosting_type'] = 'gbdt' params['objective'] = 'binary' params['metric'] = 'binary_logloss' params['learning_rate'] = 0.02 params['min_data_in_leaf'] = 30 params['num_leaves'] = 31 params['feature_fraction']= 0.15 clf = lgb.train(params, d_train, num_boost_round=100) ``` A acurácia do modelos foi de 91,23% ``` LightGBM Model accuracy score: 0.9123 Training-set accuracy score: 0.9143 ``` A Matriz de Confusão pode ser vista abaixo. ``` Confusion matrix [[43 4] [ 6 61]] True Positives(TP) = 43 True Negatives(TN) = 61 False Positives(FP) = 4 False Negatives(FN) = 6 ``` Ao analisarmos a acurácia dos modelos, o modelo Random Forest teve um desempenho melhor que o modelo Light GBM. No entanto, isso pode ser explicado principalemnte pelo tamanho da base de dados utilizada. O Modelo Light GBM tende a performar melhor com base de dados maiores. Em suma, mostramos como os modelos podem ser aplicados em Python e suas diferenças. # Referências BREIMAN, L. Random forests.Machine learning, Springer, v. 45, n. 1, p. 5–32, 2001 KE, G. et al. Lightgbm: A highly efficient gradient boosting decision tree. In:Advances inneural information processing systems. [S.l.: s.n.], 2017. p. 3146–3154.