Aprendizado Semi-Supervisionado para Detecção de Fraudes [Parte 1]
Seja para detectar falhas em um avião ou usina nuclear, seja para perceber gastos ilícitos de um deputado ou seja para apontar sonegação no imposto de renda, a arte de notar comportamentos e padrões suspeitos pode ser bastante útil em diversos cenários. Pensando nisso, preparamos uma pequena lista de procedimentos para esse tipo de tarefa. Algumas delas serão incrivelmente simples e surpreendentemente efetivas. Outras, nem tão simples assim. De qualquer forma vamos nos concentrar em técnicas de aprendizado de máquina semi-supervisionado para detecção de anomalias. Não se preocupe se isso soou confuso. Antes de mais nada, vamos explicar tanto o que são anomalias quanto o que é aprendizado de máquina semi-supervisionado. Em seguida, vamos fornecer uma explicação intuitiva do funcionamento de cada uma das técnicas aqui explicadas, assim como esclarecer suas vantagens e desvantagens. Esse trabalho é livremente inspirado em uma pesquisa em que Chandola et al (2009) compilam várias técnicas de detecção de anomalia.
Essa pesquisa não pretende ser extensiva e nem rigorosa; nossa esperança é sermos o menos complicado possível na linguagem e o mais direto possível nas explicações intuitivas. Para uma versão mais detalhada e técnica, você pode conferir implementação que fizemos diretamente no Kaggle (em inglês).
O que é uma anomalia?
“Anomalias são padrões nos dados que não obedecem bem as noções definidas como normalidade” (Chandola et al, 2009). Em outras palavras, são dados que apresentam algum comportamento estranho, distinto do padrão normal. Por exemplo, os pontos \(O_1\), \(O_2\) na imagem abaixo estão isolados e fora das regiões de normalidade (\(N_1\) e \(N_2\)), sendo assim considerados anomalias. Os pontos na região \(O_3\), embora tenham uma vizinhança, também são anomalias, pois a região inteira está fora da de normalidade.
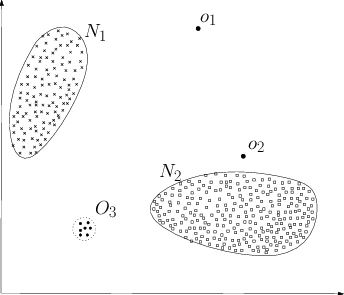
Assim sendo, uma abordagem bastante direta para detecção de anomalias seria simplesmente definir a região onde os dados normais estão presentes e classificar tudo o que aparecer fora dessa região como anomalia. No entanto, isso é mais fácil de falar do que de fazer e há alguns desafios bastante complicados que surgem em problemas de detecção de anomalias:
-
Modelar uma região que capture todas as noções de normalidade é extremamente difícil e as fronteiras entre normal e anormal geralmente não são bem definidas;
-
Anomalias podem ser o resultado de atividade maliciosa (e.g. fraudes bancárias). Nesse caso, há um adversário que está sempre tentando se adaptar para fazer com que as observações anômalas pareçam normais;
-
O que é normal pode mudar, isto é, uma noção de normalidade definida hoje pode não ser válida no futuro;
-
A noção de normalidade varia muito de aplicação para aplicação e não há um algoritmo geral o suficiente para capturá-la de forma ótima;
-
Conseguir amostrar o comportamento anormal é geralmente um dos maiores problemas em detecção de anomalias, sendo essas amostras extremamente escassas ou até mesmo inexistentes.
Para lidar com esses problemas, nós sugerimos uma abordagem semi-supervisionada, que não requer nada além de uma pequena parcela de amostras anormais.
O que é aprendizado de máquina semi-supervisionado
Aprendizado de máquina é uma ciência que utiliza métodos da ciência da computação e estatística para analisar dados. As técnicas de aprendizado de máquina surgiram dentro do campo de inteligência artificial, como um meio de permitir que os computadores aprendessem uma forma de conhecimento própria. Hoje, aprendizado de máquina se expandiu em um campo autônomo e tem obtido sucessos também em problemas que demandam raciocínio estatístico além da capacidade humana. Dentro dos regimes de aprendizado de máquina, destaca-se o de aprendizado de máquina supervisionado, que foca em problemas de previsão: tendo uma base de dados com “alvos” para cada observação (pares \((x,y)\)), a meta é aprender quais “alvos” (\(y\)) estão associados a quais dados (\(x\)). Isso é feito apresentando ao computador pares suficientes de dados e alvos, até que ele aprenda a associar um ao outro. Alguns exemplos desse tipo de problema são: identificar a presença de uma doença (alvo), dado os sintomas do paciente (dados); prever se o preço da ação de uma empresa vai subir ou cair (alvo), dado o histórico do mercado financeiro (dados); identificar de que pessoa é a face (alvo) em uma imagem (dados) ou classificar um livro (dados) em uma escola literária (alvo).
Uma limitação de aprendizado de máquina supervisionado é que pode ser extremamente custoso conseguir os alvos para cada observação (nós chamamos isso de nomear a base de dados). Por exemplo, considere o problema de prever o tema de um artigo de jornal (alvo) dado o seu conteúdo escrito (dados). Para que um computador faça isso, é preciso que antes alguém tenha lido uma grande quantidade (muitas vezes, milhares) de artigos e nomeado cada um com um tema. Assim, o computador terá acesso tanto ao conteúdo, quanto ao alvo que ele precisa prever, nesse caso o tema do artigo. Em cenários de detecção de anomalias, muitas vezes nós só temos dados que representam o caso normal, sendo extremamente difícil conseguir dados que representam anomalias. Em alguns extremos, como, por exemplo, o problema de detectar falhas em uma usina nuclear, conseguir exemplos de falhas críticas é tanto impossível quanto indesejável. Assim, com poucos ou nenhum exemplo do que é um caso anormal, o computador não tem informação suficiente para aprender os padrões estatísticos da anormalidade, tornando o problema de detectá-la extremamente difícil.
Uma possibilidade é utilizar aprendizado de máquina semi-supervisionado, em que consideramos apenas uma pequena parcela dos dados como estando nomeada e que os dados não nomeados só contêm exemplos do caso normal, que geralmente é abundante. Assim, nós utilizamos técnicas de aprendizado não supervisionado (para aprender a estrutura dos dados) nos dados não nomeados para extrair alguma noção de normalidade. Ao final dessa etapa não supervisionada, a máquina conseguirá associar cada observação com uma pontuação proporcional à probabilidade do dado ter vindo da região normal. Em seguida, usamos a parte nomeada dos dados (com exemplos tanto de anomalias, quanto do caso normal) para definir um limiar na pontuação, a partir do qual consideraremos a amostra como anômala.
OK… Talvez esse último parágrafo contenha muitas e complexas informações, o que torna a compreensão mais lenta. Pense no seguinte: primeiro, nós ensinamos a máquina apenas como é o caso normal, pois não temos (muitos) exemplos de anomalias; em seguida, nós usamos um pouco dos exemplos de casos anormais para refinar a percepção de normalidade da máquina; por fim, utilizamos o resto dos dados - com um pouco de casos anormais e muitos casos normais – para produzir uma avaliação final do nosso método de detecção de anomalias. Se você ainda não entendeu, não se preocupe. Logo mais colocaremos um estudo empírico com vários exemplos utilizando métodos de aprendizado semi-supervisionado para detectar fraudes.