Weather to detect fraud in an airplane or nuclear plant, or to notice illicit expenditures by congressman, or even to catch tax evasion. the art of realizing suspect patterns and behaviors can be quite useful in a wide range of scenarios. With that in mind, we made a small list of procedures to carry out this kind of task. Some of them will be incredibly simple and surprisingly effective. Other, not so simple. Anyway, we will focus on semi-supervised machine learning techniques for anomaly detection. Don’t worry if this sound confusing at first. Before anything, we will explain what are anomalies and what is semi-supervised machine learning. Next, we will give some intuitive explanations about the techniques here explored, as well as cast light in their advantages and disadvantages. This work is freely inspired in a survey by Chandola et al (2009).
This work does not intent to be extensive nor rigorous; out goal is to be the least complicated we can and the more intuitive as possible. For a more details and technical discussion, please check out our implementation of this work on Kaggle
What is an anomaly?
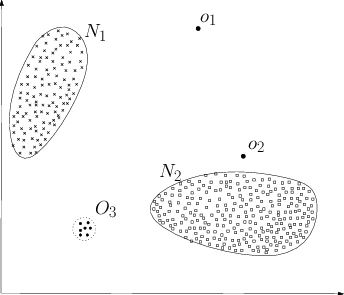
“Anomalies are patterns in data that do not conform to a well-defined notion of normal behavior” (Chandola et al, 2009). In other words, they are data are somewhat strange and distinct from normal observations. For example, points in \(O_1\), \(O_2\) in the image bellow are isolated and outside the normal region (\(N_1\) and \(N_2\)), thereby being considered anomalies. The dots in region \(O_3\), although being in a neighborhood, are also anomalies, for that whole region is outside the normal boundaries.
A fairly straightforward approach for anomaly detection would be to simple define the regions in the data where in the normal data lies and then classify everything outside that regions as anomalous. However, this is most easy said than done and there are some quite difficult challenges that arise in anomaly detection problems:
-
Modeling a regions that captures all notions of normality is extremely difficult and the frontiers between normal and abnormal are usually blurred;
-
Anomalies can be the result of malicious activities (e.g. frauds). In this case, there is an adversary that is always adapting to make anomalous observations seem normal;
-
What is normal can change, that is, a notion of normality defined today may not be valid in the future;
-
The notion of normality varies a lot from application to application and there is no general enough algorithm to capture them all in an optimized way;
-
Gathering samples from the abnormal behavior is a major challenge in anomaly detection. These samples tend to be very scarce or non existent.
To deal with this problems, we propose a semi-supervised approach, that requires only a small portion of abnormal samples.
What is semi-supervised machine learning?
In rough terms, machine learning is the science that uses computer science and statistical methods to analyze data. Machine learning techniques started in the field of artificial intelligence, as a way to allow for computers acquire their own knowledge from data. Today, machine learning has expanded in its own field and has had success in problems that demand statistical reasoning being our human limitations. In the regimes that machine learning operates on, the most prominent is the supervised one, that focus on predictions tasks: having data on pairs of labels and observations \((x, y)\), the goal is to learn how the labels are associated with the features. This is done by presenting the machine with enough samples of features and its observed labels, to the point where it can learn an association rule between them. Some examples are: identifying the presence of a disease (label), given the patient symptoms (features); identify which person (label) is in a given image (features) or classify a book (features) in a given literary school (label).
One limitation of supervised machine learning is that gathering labels can be costly. For example, consider the problem of prediction the class of an article given its written content. To teach a computer to do such tasks, we first need to collect the articles and label them with the right category. Usually, we need thousands of examples, so labeling such an amount of articles can be very time-consuming. In anomaly detection task, we often have an abundant observations of the normal case, but it is very hard to gather abnormal observations. In some extreme cases, such as nuclear plant failure detection, it is not only hard to have anomaly examples, but it is undesirable. Therefore, with little or no examples of anomalies, the computer doesn’t have enough information to learn their statistical proprieties, making the problem in detecting them extremely difficult.
One possibility is to use semi-supervised machine learning, where we consider only as small fraction of the data as being labeled and that the majority of the unlabeled data has only normal samples. Thus, we can use unsupervised machine learning techniques (that learn the structure in data) to learn some notion of normality. By the end of this unsupervised stage, the machine will be able so associate each observation with a score that is proportional to the probabilities of that observation being normal. Then, we can use some labeled data to tune a threshold for this score, below which we will consider a sample as being an anomalies.
OK… Maybe this last paragraph has a little too much information, which makes understanding slower. Think this way: first, we teach the machine only to understand how the normal case is, for we do not have (much) anomaly samples; next, we use a little of the few anomaly examples we have to fine tune our machine’s perceptions of normality; lastly, we use the rest of our data - with a few anomalies and lots of normal observations, to produce a final evaluation of our anomaly detection technique. If you still didn’t get it, don’t worry. Soon we will an empirical research with lots of examples showing how to use semi-supervised machine learning for fraud detection.