SVM em Marketing
A grande maioria das decisões que precisam ser tomadas na área de marketing necessitam de modelos preditivos. Para se obter resultados que sejam úteis para a organização, é preciso que o problema a ser resolvido seja definido da forma mais precisa possível. Dessa forma, Cui e Curry (2005) classificam as previsões em quatro contextos:
1. Previsão Pura: ocorre em casos onde o conhecimento estrutural do problema não é viável ou necessário, o objetivo é apenas resolver um problema e tomar uma decisão, não entender a sua dinâmica; 2. Previsão Robusta: neste contexto, a previsão continua um fator importante, mas não é o único objetivo, também há uma busca por compreender um panorama geral do problema, como tendências, ; 3. Previsão Analítica: neste tipo de previsão, os modelos são construídos ou adaptados para solucionar um problema específico de forma mais analítica, ou seja, o objetivo é mais compreender a estrutura do problema, mas ainda assim há acurácia nas previsões; 4. Previsão e Análise de Gaps Estruturais: neste contexto, os modelos de previsão buscam aumentar o conhecimento estrutural do processo, assim, de certa forma, o lucro é secundário em relação ao entendimento do problema.
Assim, pode-se dizer que há uma espécie de tradeoff entre a precisão da previsão e a capacidade de explicar o problema. Todavia, isso não quer dizer que uma boa previsão não seja também útil para compreender um problema.
Considerando-se esses tipos de previsão e com o desenvolvimento das áreas de marketing das organizações, as análises e modelos preditivos serão cada vez mais necessários para a tomada de decisão. Neste ponto, as máquinas de suporte vetorial geram ótimas previsões. Técnicas desse tipo aliadas à evolução da capacidade computacional e às facilidades atuais de acesso a informação geram cada vez mais dados. Dessa forma, os consumidores se tornam cada vez mais exigentes e específicos e, com isso, os clientes estão cada vez mais segmentados.
Assim, para atender a essas necessidades dos consumidores, os gestores precisam estar mais atentos ao planejamento e às estratégias de marketing para adequá-las aos interesses dos consumidores e também para atingir os mais diversos perfis de consumo. Para este fim, uma opção baseada no SVM é o Support Vector Clustering (SVC), que pode ser usado para a segmentação de mercado. Por exemplo, é possível segmentar os clientes de um e-commerce de acordo com a cesta de consumo e características pessoais de cada um, como idade, estado civil, grau de instrução etc.

O marketing direto é um ramo em que busca-se obter vendas de pessoas que já possuem certo interesse pela empresa, como por exemplo cupons de desconto para clientes. Assim, faz-se necessário conhecer o perfil da base de consumidores. Para isso, Shin e Cho (2006) construíram um modelo usando SVM com o objetivo de prever a possibilidade de resposta dos consumidores a uma promoção de produto ou serviço.
A precisão do modelo é pautada na quantidade de consumidores que responderão de forma positiva à promoção do produto ou serviço, quanto maior o número de casos positivos, maior a precisão do modelo.
Dessa forma, o SVM buscar por classificar os consumidores entre respondentes e não-respondentes. Embora a metodologia do SVM seja muito útil e ofereça ótimos resultados, esse método também possui algumas complicações na aplicação quando há uma grande quantidade de dados. Há também casos com classes desbalanceadas, que são ocasiões em que há uma desproporção muito grande entre os dados para cada tipo de consumidor ou perfil, por exemplo o número de compradores gerados de um e-mail marketing vai ser muito pequeno em relação ao total que foi enviado a milhares de pessoas.
Outro ponto relevante do SVM, é que diferentemente de outros métodos de aprendizado de máquina, ele fornece um valor binário, isto é -1 ou 1. Para solucionar esta dificuldade e descobrir a propensão de compra do consumidor, é possível estimar a probabilidade com base na distância entre o padrão dos dados e o limite de decisão (o valor que determina se aquele dado pertence a uma classe ou não), ou seja, o padrão que está mais distante do limite de decisão possui maior probabilidade de pertencer à classe representada, e assim é possível estimar as probabilidades de compra dos clientes.
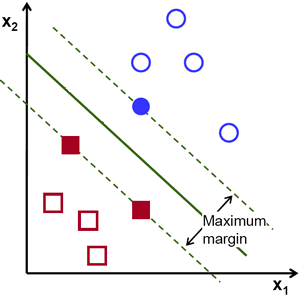
Ainda no Marketing Direto, é possível explorar o SVM em conjunto com sistemas especialistas - sistemas que buscam executar funções humanas em decisões - para fornecer recomendações de produtos personalizados para cada cliente utilizando os dados das preferências dos próprios consumidores. Atualmente, isso é bastante utilizado por e-commerces como a Amazon. Para avaliar as preferências dos consumidores e dar sugestões de consumos, dois métodos possíveis são o Content-Based System e o Collaborative System.
No Content-Based System, as recomendações são feitas com base nas características do produto e no perfil do consumidor. A avaliação das características é feita com base na descrição do produto e relacionada com o consumo passado do cliente. Isto é, busca-se oferecer sugestões similares ao que o consumidor já adquiriu ou se interessou.
Já o Collaborative System faz recomendações por meio da combinação de preferências de clientes semelhantes. Por exemplo, os clientes A e B compraram uma bola de futebol. Em seguida, o cliente A comprou uma chuteira, assim, assume-se que eles têm preferências semelhantes para outros tipos de produtos e recomenda-se uma chuteira para o cliente B.
Dessa forma, a abordagem em problemas cotidianos de marketing em empresas pode ser melhorada com o uso de aprendizado de máquina e, mais especificamente, o SVM. Em um post futuro, abordaremos um exemplo prático desse tipo de problema.
Referências:
CUI, Dapeng; CURRY, David. Prediction in marketing using the support vector machine. Marketing Science, v. 24, n. 4, p. 595-615, 2005.
SHIN, HyunJung; CHO, Sungzoon. Response modeling with support vector machines. Expert Systems with applications, v. 30, n. 4, p. 746-760, 2006.