Aprendizado de Máquina
Formalmente:
Aprendizado de máquina é definido por um sistema computacional que busca realizar uma tarefa \(T\), aprendendo a partir de uma experiência \(E\) procurando melhorar uma performance \(P\).
Mas afinal, o que isto quer dizer?

Basicamente, um algoritmo pode aprender a atingir um objetivo a partir de um grande volume de dados - suas experiências. Eis um exemplo para ficar mais claro. Suponha que nossa tarefa seja prever o resultado de um jogo de futebol. Como podemos fazer isso?
Poderíamos fornecer ao computador dados sobre o técnico, composição do time, formação tática, etc., seguidos dos resultados das partidas. Com um grande volume de dados em formato de pares (variáveis, resultados), esperamos que o computador possa aprender quais padrões levam à vitória. Também esperamos que o computador acerte mais conforme lhe apresentamos mais dados, pois ele terá mais exemplos de padrões que pode generalizar para situações ainda não vistas. Assim, quanto mais dados, isto é, quanto mais experiência, melhores serão os resultados, isto é, melhor será a nossa performance
Aprendizado Supervisionado
Isto é o que chamamos de Aprendizado de Máquina Supervisionado: Quando tentamos prever uma variável dependente a partir de uma lista de variáveis independentes. Por exemplo:
| Var. Independentes | Var. Dependentes |
|---|---|
| Anos de Carreira, Formação, Idade | Salário |
| Idade do Carro, Idade do Motorista | Risco de Acidente Automotivo |
| Texto de um livro | Escola Literária |
| Temperatura | Receita de venda de sorvete |
| Imagem da Rodovia | Ângulo da direção de um carro autônomo |
| Histórico escolar | nota no ENEM |
Note que a característica básica de sistemas de aprendizado supervisionado é que os dados que utilizamos para treiná-los contém a resposta desejada, isto é, contém a variável dependente resultante das variáveis independentes observadas. Nesse caso, dizemos que os dados são anotados com as respostas ou classes a serem previstas.
Dentre as técnicas mais conhecidas para resolver problemas de aprendizado supervisionado estão regressão linear, regressão logística, redes neurais artificiais, máquina se suporte vetorial (ou máquinas kernel), árvores de decisão, k-vizinhos mais próximos e Bayes ingênuo. Aprendizado de máquina supervisionado é a área que concentra a maioria das aplicações bem sucedidas e onde a maioria dos problemas já estão bem definidos.
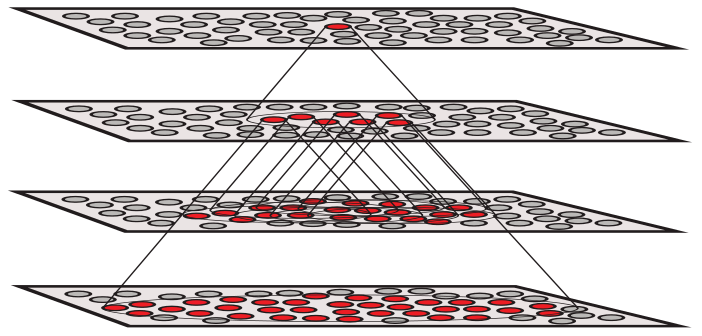
Aprendizado Não Supervisionado
Mas nem todos os problemas podem ser resolvidos desta forma. Em alguns casos, conseguir dados anotados é extremamente custoso ou até mesmo impossível. Por exemplo, imagine que você é dono de um comércio e quer conhecer o perfil dos seus consumidores. Pode haver um perfil de consumidor que sempre compra vinho e queijo ou que compra carne e carvão ou ainda leite em pó e fralda. Se esse for o caso, colocar esses produtos em prateleiras distantes pode aumentar vendas, já que aumentará o tempo e o percurso do cliente no mercado. No entanto, nesse caso não estamos anotado para cada compra à qual perfil o consumidor pertence. Mais ainda, sequer sabemos quantos perfis de consumidores há.
Nesse caso, o computador terá que descobrir os perfis sem dados anotados e precisaremos de métodos de aprendizado não supervisionados. Uma opção seria observar nos registros de compras se existem padrões repetidos e que permitiriam a inferência de um grupo ou perfil de consumidor. Outra opção seria ver diretamente quais produtos são frequentemente comprados juntos e, então, aprender uma regra associativa entre eles.
De uma forma geral, com aprendizado não supervisionado queremos achar uma representação mais informativa dos dados que temos. Geralmente, essa representação mais informativa é também mais simples, condensando a informação em pontos mais relevantes. Alguns exemplos são:
| Dados | Forma Representativa |
|---|---|
| Transações bancárias | Normalidade da transação |
| Registros de Compras | Associação entre produtos |
| Dados Multidimensionais | Dados com dimensão reduzida |
| Registros de Compras | Perfil dos consumidores |
| Palavras em um texto | Representação matemática das palavras |
Outros exemplos de aplicações de aprendizado não supervisionados são sistemas de recomendação de filmes ou músicas, detecção de anomalias e visualização de dados. Dentre as técnicas mais conhecidas para resolver problemas de aprendizado não supervisionado estão redes neurais artificiais, Expectativa-Maximização, clusterização k-médias, máquina se suporte vetorial (ou máquinas kernel), Clusterização Hierárquica, word2vec, análise de componentes principais, florestas isoladoras, mapas auto-organizados, máquinas de Boltzmann restritas, eclat, apriori, t-SNE. Problemas de aprendizado não supervisionado são consideravelmente mais complicados do que problemas de aprendizado supervisionado, principalmente porque não temos a reposta anotada nos dados. Como consequência, é extremamente complicado e controverso avaliar um modelo de aprendizado não supervisionado e esse tipo de modelo está na fronteira do conhecimento em aprendizado de máquina.
Aprendizagem por reforço
A terceira abordagem de aprendizagem de máquinas é a chamada “aprendizagem por reforço”, em que a máquina tenta aprender qual é a melhor ação a ser tomada, dependendo das circunstâncias na qual essa ação será executada.
O futuro é uma variável aleatória: como não se sabe a priori o que irá acontecer, é desejável uma abordagem que leve em consideração essa incerteza, e consiga incorporar as eventuais mudanças no ambiente do processo de tomada da melhor decisão. Essa ideia de fato deriva do conceito de “aprendizagem por reforço” da psicologia, no qual uma recompensa ou punição é dada a um agente, dependendo da decisão tomada; com o tempo e a repetição dos experimentos, espera-se que o agente consiga associar as ações que geram maior recompensa para cada situação que o ambiente apresenta, e passe a evitar as ações que geram punição ou recompensa menor. Na psicologia, essa abordagem é chama de behaviorismo e tem B. F. Skinner como um dos principais expoentes, um famoso psicólogo que, dentre outros experimentos, usou a ideia de recompensas e punições para treinar pombos para conduzir mísseis na Segunda Guerra Mundial.
Essa mesma ideia é vista no aprendizado de máquinas: a máquina observa um “estado da natureza” dentre o conjunto de cenários futuros possíveis e, com base nisso, escolhe uma ação a se tomar e recebe a recompensa associada a essa ação específica e nesse estado específico obtendo, assim, a informação dessa combinação. O processo se repete até que a máquina seja capaz de escolher a melhor ação a se tomar para cada um dos cenários possíveis a serem observados no futuro.
Ilustrando com um exemplo bem simples: suponha que você queira adestrar seu cão a se sentar ao seu comando por essa abordagem. De primeira, dificilmente o animal executará o comando requerido, e você responde a isso dando um “reforço negativo” (punição), repreendendo-o verbalmente, com suas expressões faciais ou mesmo com uma pancada de jornal (ou algo mais hostil, a depender do seu temperamento…). Quando o cão se aproxima do que deveria fazer, você pode dar “reforços positivos” como sinais de aprovação ou incentivo. Se o cão de fato sentar após o comando, você lhe dá uma recompensa - um biscoitinho, por exemplo. Com várias repetições desse mesmo experimento, espera-se que, com o tempo, o cão passe a associar a relação de “causa-efeito” entre o comando e a recompensa a ser recebida, e com isso “aprenda” a obedecer a esse comando. O famoso experimento do “cão de Pavlov” ilustra bem esse paradigma de aprendizagem. Ivan Pavlov foi um cientista russo notório por apresentar a ideia do “reflexo condicionado”, baseado no seguinte experimento: apresentando um pedaço de carne a um cão, o animal passa a salivar, desejando o alimento. Em vez de apresentar apenas a carne, Pavlov soava uma campainha sempre que isso acontecia; com a repetição, o cão passava a associar os dois “estímulos” (carne e campainha) e salivar assim que ouve a campainha.
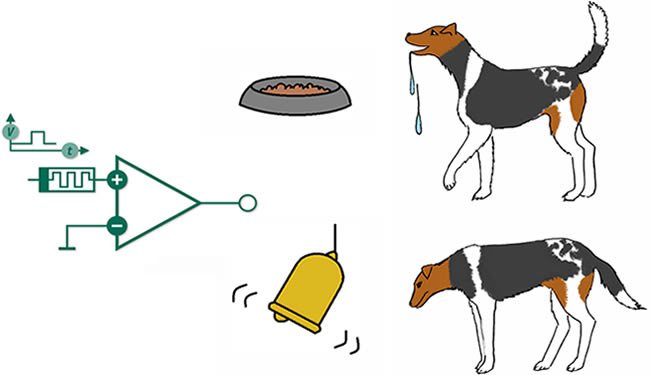
Essa ideia é bastante versátil quando a transportamos para o âmbito da ciência de dados: em vez de adestrar cachorros, podemos por exemplo construir uma máquina que monta portfolios no mercado financeiro e que ajusta a combinação de ativos comprados/vendidos a depender da “recompensa” (retorno financeiro) da carteira anterior e da evolução (“estados”) do mercado. Ou ainda um automóvel que dirige “sozinho”, que toma decisões dependendo do cenário que observa ao redor, recebendo recompensas negativas quando colide com o ambiente ou com outros veículos, e com repetidas etapas, aos poucos “aprenda” a contornar os obstáculos.

Vamos mais além: voltando ao exemplo do adestramento de cães, suponha que, depois de tê-lo ensinado a sentar com sucesso, você queira fazer um teste de obediência - fazer o cão ficar sentado enquanto você anda para trás, até chegar a uma distância de cinco metros dele. Caso o cão se sente, você dá a ele o biscoitinho (assim como antes); mas caso ele não se levante até você ficar a cinco metros dele, você dá a ele uma recompensa maior (um pedaço de bife, por exemplo). Como o cão poderia ganhar a recompensa maior? Note que agora o cão tem uma “escolha difícil”: ele pode simplesmente sentar (já que ele já aprendeu essa tarefa) e ganhar sempre o biscoito, assim como pode “explorar” novas possibilidades - no caso, ficar parado mesmo com o dono longe - para ver se eventualmente não há uma recompensa maior ainda. O dono continuará fornecendo reforços positivos e negativos enquanto anda para trás, elogiando-o se ficar parado e repreendendo-o caso saia da posição; mas será que o animal está disposto a abrir mão da recompensa que ele já tem “garantida”?
Essa situação ilustra um trade-off: o animal pode escolher por “testar” novas combinações de ações ótimas em uma sequência de “estados” não realizadas anteriormente em busca de uma recompensa maior, mas não imediata (o chamado “exploration”); ou simplesmente se ater à recompensa que se obtém através de uma ação já conhecida (o chamado “exploitation”). Veja como essa ideia pode se estender facilmente para outros contextos; em finanças, por exemplo, reflete bem o grau de aversão ao risco de um agente econômico - o quanto ele está disposto a correr mais riscos em busca de retornos maiores, ou está disposto a correr menos risco e obter um retorno menor, porém mais seguro.

Fazer a máquina ser capaz de encontrar o meio termo ótimo entre “exploration” e “exploitation” é um dos principais desafios da aprendizagem por reforço, e é bastante pertinente para aplicações mais complicadas, como ensinar uma máquina a jogar xadrez, por exemplo: como é bem sabido, uma estratégia vencedora frequentemente envolve abrir mão de vantagem imediata, ou até mesmo sacrifício de peças, visando ao sucesso a longo prazo - um bom jogador deve ser capaz de levar em consideração as consequências de sua jogada várias rodadas adiante, e sabendo que a resposta do oponente também estará visando a um benefício futuro, e assim por diante.
Qual das três abordagens é a melhor?

A resposta a essa pergunta depende do que você está analisando. Cada problema possui suas peculiaridades, e uma maneira de resolução que funcionou bem para o problema A pode ser desastrosa para um outro problema B. Por isso, ao trabalhar com informática, data science, computação, machine learning, ou máquinas em geral, tenha em mente a seguinte “lei”:
A MÁQUINA NÃO FAZ O QUE VOCÊ QUER: ELA FAZ O QUE VOCÊ MANDA!
A máquina é, acima de tudo, um instrumento de conveniência; o desempenho da inteligência artificial está inteiramente condicionado à inteligência humana de quem a treinou. Fatores como o dilema viés-variância exigem um cuidado do pesquisador para que a máquina forneça de fato os resultados requeridos. Técnicas de regularização e validação cruzada também são mecanismos importantes para “guiar” a máquina e garantir um meio termo entre acurácia na amostra e poder de generalização. “Saber mandar” é algo que nenhuma máquina pode fazer por você. Por isso, conhecer bem o problema a ser solucionado é sempre o primeiro passo, pois esse é o passo essencial para que o pesquisador tenha controle sobre a máquina, ao invés do contrário…
