Estatística Espacial
Estatística Espacial consiste no estudo, caracterização e modelagem de variáveis aleatórias que apresentam uma estrutura espacial ou espaço-temporal. O estudo tem por objetivo determinar um fenômeno em determinado espaço geográfico que pode ocorrer ou não ao longo do tempo.
Para fazer uma avaliação completamente precisa seriam necessários coletar todos os casos desse evento; o que é proposto é que sejam coletadas amostras em locais diferentes (em períodos diferentes se for o caso) e, a partir delas, sejam criadas previsões para as áreas sem coleta de amostra. Um exemplo de previsão para tomada de decisão será elucidado ao fim desse post.
Exemplo de dados que utilizam Estatística Espacial são estudos de criminalidade, para avaliar concentração de crimes por bairros, por exemplo, ou estudos de clima, para estudar precipitação de chuva em uma região.
Dados
Os dados utilizados na Geoestatística são aqueles que as principais características deles estão relacionados às coordenadas espaciais e ao tempo.
Eventos pontuais: Tais eventos são marcados pela localização ou momento no tempo. Assim, podemos estimar o número esperado de eventos em uma área, ou seja, estima a intensidade deles.
Dados de superfícies: Nesse caso, os eventos não tem uma precisão (latitude e longitude), mas estão definidos em um aglomerado de dados em um espaço (bairro, distrito, município) ou tempo. É comum termos a visualização desses dados nos chamados mapas climáticos.
Tipos de Dados
Abaixo, é possível observar os tipos de dados analisados em Estatística Espacial.
| Tipos de Dados | Exemplo | Problemas Típicos | |
|---|---|---|---|
| Análise de Eventos Pontuais | Eventos Localizados | Ocorrência de Doenças | Determinação de Padrões |
| Análise de Superfícies | Amostra de campo e matrizes | Depósitos Minerais | Interpolação e medidas de Incerteza |
| Análise de Áreas | Polígonos e Atributos | Dados Censitários | Regressão e Distribuições Conjuntas |
Workflow
O tratamento e análise dos dados consistem em aplicar um método de interpolação para o melhor entendimento do fenômeno estudado. A interpolação é uma técnica de transformação de eventos pontuais para dados de superfície.

Tal análise segue o fluxo acima, no qual passamos por oito passos.
- Coleta dos dados: Seja por meio de extração de materiais ou por uma pesquisa de campo.
- Pre-processamento dos dados: uma etapa não obrigatória, que avalia se os dados utilizados não apresentam alguma inconsistência.
- Modelagem da estrutura espacial: alguns métodos requerem que as amostras sejam modeladas usando um semivariograma ou uma função de covariância para definir se a amostra tem mais similaridade com os elementos próximos ou com o grupo todo.
- Definição da estratégia de busca: nessa etapa são definido quantas amostras serão utilizadas na interpolação.
- Previsão de valores: com o modelo pronto, faremos a efetivamente a interpolação tendo geralmente por resultado um mapa com as previsões para as localizações sem amostra.
- Quantificação da incerteza das previsões: ao mesmo tempo que são geradas previsões sobre valores sem amostras, avaliamos os erros na previsão. Isso ocorre, pois certos métodos de interpolação não são determinísticos e assim possibilitam a avaliação de erros em seus cálculos.
- Verificação: etapa na qual é verificado com amostras não utilizadas se os valores das previsões condizem com elas. Caso estejam destoantes, será necessário reavaliar os passos um a três.
- Uso dos dados de superfície para tomada de decisão.
Métodos de interpolação
Existem duas categorias de métodos de interpolação: determinísticos e geoestatísticos. Os métodos deterministicos calculam os valores de cada ponto baseados diretamente nas amostras próximas. Já os métodos geoestatísticos utilizam a relação estatística entre as amostras levantadas.
Métodos determinísticos
Tais métodos levam em conta que todo o conjunto da amostra se comporta de forma regular e por isso não contabilizam por erros. Um exemplo é o método da média móvel que avalia a média das amostras dentro de certo raio para determinar o valor do ponto sem amostra. Outro exemplo é o Inverse Distance Weighted (IDW) que também avalia as amostras mais próximas, porém atribui pesos para o valor de cada amostra a fim de determinar o ponto sem amostra.
Métodos geoestatísticos
Tais métodos levam em conta a autocorrelação dos dados - as relações estatísticas entre o pontos. Por isso que além de produzir uma previsão, eles também produzem um nível de certeza do resultado.
O Kriging é um dos métodos de interpolação geoestatístico que assume que a distância ou direção dos pontos reflete uma correlação espacial que pode ser usada para explicar a variação da superfície. A fórmula do Simple Kriging é semelhante a do IDW:
\[\hat{Z}(s_0) = \sum_{i=1}^{N}\lambda_iZ(s_i)\]Sendo: (s_0) a previsão para um local (λ_i) o peso para alocalização (i) (Z(s_i)) o valor da amosta na localização (i) (N) o número de amostras
A diferença entre o Simple Kriging e o IDW é que o peso do IDW depende somente da distância para as amostras. Enquanto que o Simple Kriging considera a relação espacial com as amostras por meio de um varioagrama.
Os métodos Kriging são usados quando há uma correlação espacial nas amostras. O Kringing é um método de multi-etapas que serão discutidas a seguir.
Etapa 1: Análise dos dados de entrada
Para isso iremos avaliar se os dados são distribuídos aleatoriamente ou se eles parecem agrupados com uma análise de padrões. Além disso eliminaremos os pontos que:
- as coordenadas são inválidas
- os valores do fenômeno são indefinidos
- são duplicados Para o caso de uma amostra muito grande, o recomendado é dividir o conjunto de dados em duas partes: uma para interpolação e outra para verificação.
Etapa 2: Cálculo da variação do conjunto de dados
Nesta etapa, são determinados os pontos de entrada que vão contribuir para o valor de saída, limitados pela distância limite previamente especificada e dependendo também do número mínimo e máximo de pontos. Neste caso, são ignorados os pontos de entrega que estão acima da distância limite e são calculadas as distâncias de cada amostra com o ponto a ser buscado.
Etapa 3: Variação e variogramas
Como a primeira lei da geografia de Tobler diz:
“Everything is related to everything else, but near things are more related than distant things”
Assim, para determinar a concentração de um fenômeno em um ponto, temos de modelar um variograma que leva em consideração essa lei. O primeiro passo para criar o variagrama é avaliar a distância entre todos os possíveis pares de amostras.
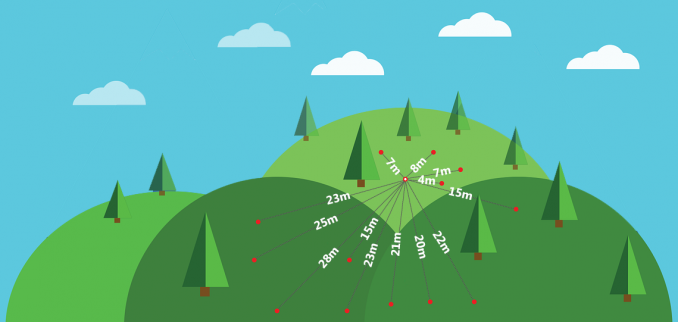
A imagem acima exemplifica a distância ((h)) entre todas as amostras e uma amostra em específico. Tal passo deve ser repetido para cada uma das outras amostras, levantando a distância entre todos dois pontos possíveis.
Ao mesmo tempo, para cada dois pontos iremos calcular a variância desses dois pontos pela seguinte fórmula:
\[Semivariância(h) = \sqrt{\sum_{i=0}^{N}(Z(s_i)-\overline{Z(s)})^{2}}\]Uma vez feito isso, plotamos então em um gráfico. Utilizamos o valor da semivariância calculado anteriormente como o eixo $X$ e a distância até o local que queremos determinar a amostra como o eixo $Y$. Tal gráfico é o variograma empírico:
 \(Semivariância(h) x Distância\)
\(Semivariância(h) x Distância\)
Etapa 4: Avaliação de tendência
Precisamos transformar nossos pontos em uma função. Muitas vezes, os pontos se encontram em uma distância única além disso a combinação de possibilidades pode ser muito grande. Nesses casos podemos considerar agrupar por grupos de distância, chamados de lag bins. Nessa situação, tiramos uma média de cada lag bin, indicado pelo símbolo de adição no gráfico abaixo. Então criamos um gráfico a partir dessas médias (indicado pela linha azul no gráfico abaixo). Esse é o semivariograma.

Etapa 5: Modelar variograma
Tendo o variograma empírico, temos que avaliar com qual modelo ele mais se assemelha. Esse processo é chamado de fitting. Fazemos isso para poder avaliar os pontos que as nossas amostras não contemplam. Nele analisaremos nosso variograma com cinco modelos que o Kringing provê:
- Circular
- Spherical
- Exponential
- Gaussian
- Linear


Ao encontrar qual modelo nossos dados se adequam melhor, utilizamos a fórmula que esse modelo provê para chegar até os pesos das amostras. Ao utilizar um desses modelos, levamos em consideração que nem todas as amostras de proximidades semelhantes tem o mesmo impacto no ponto que buscamos. Outro método da geoestatística, o IDW (Inverse Distance Weighing), assume que todos os pontos tem a mesma influência e essa seria a diferença entre os dois.
Cada fórmula possui três elementos principais: o Range, o Sill e o Nugget.O Range é a distância até que as amostras se tornam irrelevantes para o ponto estudado; no gráfico isso é representado como o momento em que o modelo não varia mais. O Sill é o valor da semivariância máxima que é atingida no momento em que o modelo não varia mais. O Nugget é o valor em que o modelo corta o eixo Y. Abaixo temos uma representação de cada um destes três elementos.
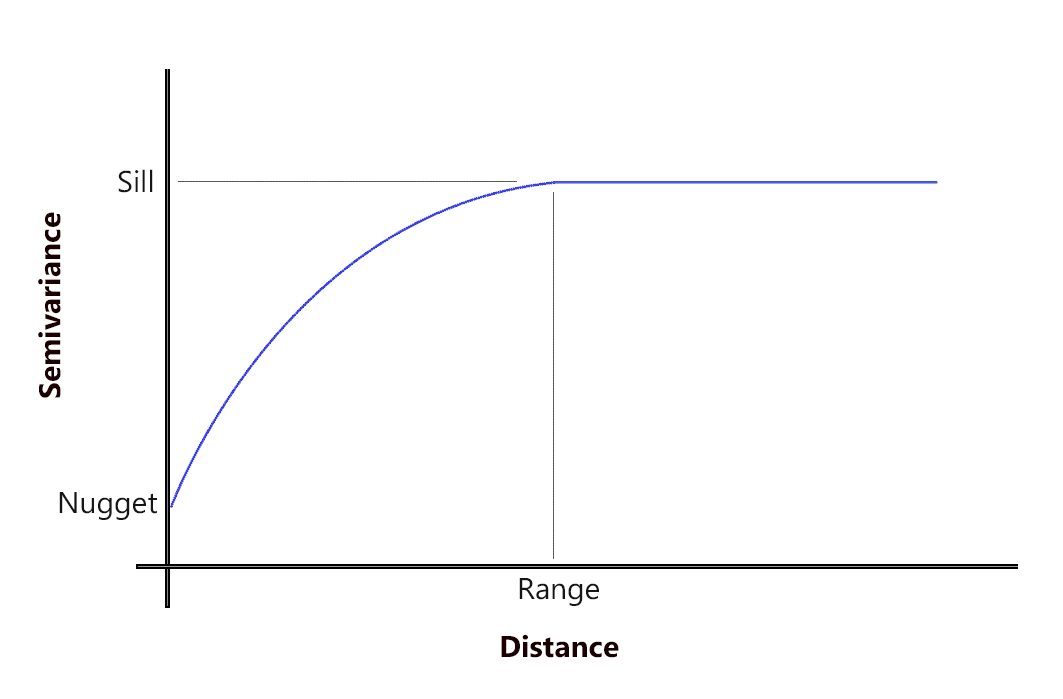
Tendo feito o fitting, utilizamos os valores do Range ((r)), do Sill ((\alpha)) e do Nugget ((C_0)) obtidos do modelos na fórmula. Agora resta apenas a distância ((h)) na fórmula. Faremos uma matriz de todas as possibilidades de relações de amostras e para cada distância, calcularemos o valor da semivariância. Resultando em uma matriz de semivariâncias, por exemplo:
[C11 C12 C13] [4 1.1 0.62]
|C21 C22 C23| = |1.1 4 0.62|
[C31 C32 C33] [0.62 0.62 4 ]
Também é necessário criar uma matriz de semivariâncias de todas as amostras em relação ao ponto a ser obtido. Nesse caso, o valor da distância ((h)) na fórmula será a distância entre a amostra e o ponto a ser observado ((Z(0))), por exemplo:
[C10] [1.48]
|C20| = |1.48|
[C30] [1.1 ]
Com essas matrizes, adicionamos mais uma linha e uma coluna na matriz entre as amostras para ser contabilizado como o erro e a invertemos. Em seguida, multiplicamos o resultado pela matriz de distâncias até o ponto a ser obtido ((Z(0))):
[w1] [4 1.1 0.62 1]-1 [1.48] [ 0.353]
|w2| = |1.1 4 0.62 1| |1.48| = | 0.353|
|w3| |0.62 0.62 4 1| |1.1 | | 0.293|
[λ ] [1 1 1 0] [1 ] [-0.505]
O resultado são os pesos das amostras em relação ao ponto a ser obtido ((Z(0))). Com os pesos, utilizamos a fórmula do kriging, somamos a multiplicação dos peso pela concentração da amostra:
\[\hat{Z}(s_0) = \sum_{i=1}^{N}\lambda_iZ(s_i)\]Ao fazer o somatório dos valores da multiplicação do peso com o valor da amostra em questão, obtemos o valor do local sem amostras. Após obter o resultado de um local, esse processo deve ser repetido para todo os pontos do mapa.
Exemplo
Digamos que temos uma propriedade, que se extende por 5.5km de largura e comprimento, na qual queremos saber a melhor localidade para extração de ouro. Para tal, extraímos amostras de alguns lugares de nossa propriedade. Abaixo são indicadas as latitudes (x(i)), longitudes (y(i)) e a concentrações (Z(s_i)) encontradas:
| Amostra $i$ | $x(i)$ | $y(i)$ | $Z(s_i)$ |
|---|---|---|---|
| 0 | 0.3 | 1.2 | 0.47 |
| 1 | 1.9 | 0.6 | 0.56 |
| 2 | 1.1 | 3.2 | 0.74 |
| 3 | 3.3 | 4.4 | 1.47 |
| 4 | 4.7 | 3.8 | 1.74 |
Para determinar a maior concentração, utilizaremos a biblioteca PyKrige que realiza os cálculos do Kriging. Ela pode ser instalado no anaconda com o comando:
conda install -c conda-forge pykrige
Abaixo um simples exemplo de Ordinary Kringing. Ele se inica com a criação de um array de amostras com a posição (X, Y) e o valor de concentração do fenômeno.
Logo em seguida é criado o grid em que serão exibidos os resultados. Tal grid é composto pelo eixo (X) e (Y) em que cada um possui um valor inicial, um final e um espaçamento entre cada ponto.
Na criação do Ordinary Kringing são passados todos os valores do eixo (X) das amostras, em seguida do eixo (Y) e por fim a concentração do fenômeno. Além desses parâmetros também é passado o tipo de modelo de variograma. Caso nenhum modelo seja passado, a biblioteca irá automaticamente tentar fazer o fitting dos dados em um modelo.
Após criado a variável Ordinary Kringing, executamos ele. O resultado é o grid de valores e a variância do grid.
Essa biblioteca também permite a execução de outros tipos de Kringing.
import numpy as np
import pykrige.kriging_tools as kt
from pykrige.ok import OrdinaryKriging
# array de amostras
amostras = np.array([[0.3, 1.2, 0.47],
[1.9, 0.6, 0.56],
[1.1, 3.2, 0.74],
[3.3, 4.4, 1.47],
[4.7, 3.8, 1.74]])
# eixos grid com inicio, fim e espacamento
gridx = np.arange(0.0, 5.5, 0.5)
gridy = np.arange(0.0, 5.5, 0.5)
# Criação do Ordinary Kringing
OKringing = OrdinaryKriging(amostras[:, 0], amostras[:, 1], amostras[:, 2], variogram_model='linear',
verbose=False, enable_plotting=False)
# Executa o Kringing
z, ss = OKringing.execute('grid', gridx, gridy)
# escreve o resultado em um arquivo
kt.write_asc_grid(gridx, gridy, z, filename="output.asc")
Resultado
Como observamos no resultado abaixo, a maior concentração de ouro na propriedade encontra-se no canto superior esquerdo:
latitude: 5.5
longitude: 4.5
concentração: 1.74
Os valores ao redor desse ponto também são os mais altos, sendo assim o melhor ponto para extração.

Referências
Bailey and Gatrell. Ordinary Kriging, Ch. 5.5. Michigan State University. pdf.
Monteiro, A. M. V., Câmara, G., Carvalho, M. S., & Druck, S. (2004). Análise espacial de dados geográficos. Brasília: Embrapa.
Royle, A. G., F. L. Clausen, and P. Frederiksen. “Practical Universal Kriging and Automatic Contouring.” Geoprocessing 1: 377–394. 1981
Tobler W., (1970) “A computer movie simulating urban growth in the Detroit region”. Economic Geography, 46(Supplement): 234–240.
http://desktop.arcgis.com/en/arcmap/10.3/tools/3d-analyst-toolbox/how-kriging-works.htm
https://gisgeography.com/semi-variogram-nugget-range-sill/
http://www.dpi.inpe.br/gilberto/tutorials/software/geoda/tutorials/w12_kriging_slides.pdf